Kaggle首战记录(1)-English Language Learning-比赛简介及读题
第一次参加kaggle的比赛,选择了这个比赛,现在距正式做已经一周时间了,发现做这个能让自己注意很多深度学习的细节(例如显存等平时上课看论文不太关心的),而且自己能在反思中收获很多东西。刚好一周 41hours 的GPU配额快用完了。因此决定把自己的比赛过程记录下来。
比赛简介
时间

内容
训练一个模型,评估 8-12 年级英语语言学习者 (ELL) 的语言能力,输入是每个学生的写作文本(长文本),输出是六个维度的评分,评分范围为1-5分,评分是离散的,0.5分为一个间隔。
需要评分的六个维度分别为:cohesion syntax vocabulary phraseology grammar conventions。中文的直译是:连贯性、句法、词汇、短语、惯例用法(有一说一这些已经对非英语母语者不友好了qaq)。
评估模型的好坏有两个赛道,一个是质量赛道,一个是效率赛道。
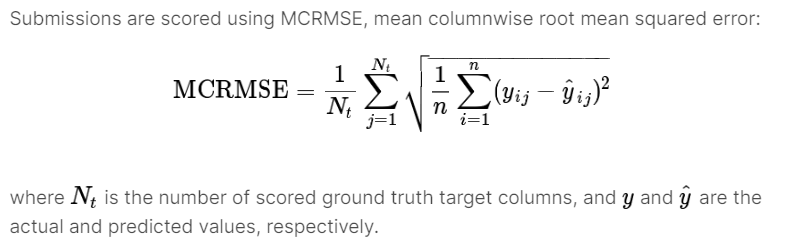
质量赛道的评估函数为类MSE函数,其中N_t就是6,n是总测试样本数:
效率赛道在此基础上考虑运行时间(只允许在CPU上运行),函数为:
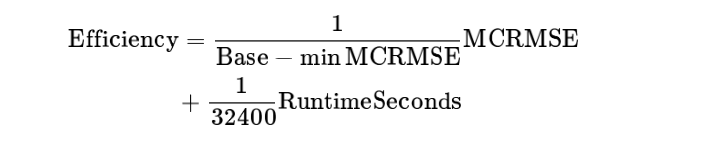
其中Base是baseline的MCRMSE,minMCRMSE是榜上的最好MCRMSE。
读题
首次参加比赛还是有很多不懂的,这里只是抛砖引玉写自己的理解而已(毕竟现在在质量赛道还是排名很后的orz)。
首先,回归模型和分类模型是需要斟酌的,回归模型的好处是损失函数一般用MSE,和评估函数很接近;为什么考虑分类模型呢?这是因为评分是离散的,可以看成是分类,而且分类给人的感觉就比较容易达到高分。但是分类模型的损失函数——交叉熵及其变体,都不会考虑到分错的严重程度,比如1分的打成3分明显比打成5分好一点,我的初步思考是在生成标签的时候做一些手脚,比如标签平滑时对远处的标签赋为更小甚至负值(当然这样损失函数的计算要注意),但这样有没有理论依据,说实话我还是太菜了没想出来,所以采用了回归模型。
其次,这几个指标能不能一起训练?我的baseline(其实也是我目前的次优分数)就是直接在预训练模型后加两层linear——这导致了微调时预训练模型是同时要去适应六个维度的,细看六个维度,cohesion是paragraph-level的,syntax、grammar是sentence-level的,而vocabulary、conventions、phraseology虽然都是句子内部的,但侧重点又有所不同,所以同时训练结果必是比较差的。但是同时训练的好处是:它能在效率赛道上竞争!毕竟你让CPU跑一次大模型和跑两次大模型所用时间实在是天差地别。之后也会提到,在数据增强的时候,这几种的数据增强方向绝对是有不同的。
其他的后面想到再在后面的文章提了,或者在这里更新。