Kaggle首战记录(3)-English Language Learning-baseline的设计和训练
一个模型训练效果的好坏除了模型本身,还很依赖于训练资源——数据和CPU
baseline的设计和代码
基于上述原因的权衡,baseline采取roberta-base + 两层全连接层的模式。采用roberta最后一层的隐藏层的第一个向量(也就是CLS的embedding),经过全连接层——batchnorm层——relu层——全连接层——sigmoid到(0, 6)作为输出。损失函数采用MSE。
batchnorm是代替dropout的正则化方法,但用在此是有疑问的 。经过测试,roberta大概占1700MB显存,使用AdamW优化器的情况下,结合上一篇文章的数据处理方法(一个句子最多5个子句,说明一个batch的向量数最多是batchsize * 5),刚好能支撑batchsize = 4的情况(这就是不选deberta的原因——参数量大、训练慢,而且batchsize更小)。但是batchnorm对小批量的影响肯定会比较差。
初始化部分的代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 path = '../input/feedback-prize-english-language-learning/train.csv' import pandas as pd'full_text' ] = data['full_text' ].apply(lambda x: x.strip())import torchfrom torch import nnimport torch.nn.functional as Fimport numpy as npimport randomdef init_seeds (seed=7 ):if seed == 0 :True False "cuda" if torch.cuda.is_available() else "cpu" 42 )from transformers import RobertaTokenizer, RobertaModel'../input/roberta-base' )'../input/roberta-base' ).to(device)
网络设计
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 class Class_Pool_Net (nn.Module):def __init__ (self, batch_size, pretrained_model, device ):super (Class_Pool_Net, self).__init__()768 , 256 ).to(device)256 ).to(device)256 , 6 ).to(device)def forward (self, x ):'last_hidden_state' ][:,0 ].reshape([self.batch_size, -1 , 768 ])input =output_embedding, output_size=(1 , 768 )).squeeze(1 ) 6 return y6def change_batch_size (self, size ):
评价函数
评价函数小抄了一手别人的代码,因为刚开始自己一直理解错了,以为是横向的mse,而且也没加根号,导致自己结果一直很难看,后来没想到是纵向的。
1 2 3 4 5 6 7 8 9 10 11 12 13 from sklearn.metrics import mean_squared_errordef evaluate_function (y_preds, y_trues ):1 ]for i in range (idxes):False ) return mcrmse_score
训练函数
学习率的设置
这里有一个坑,刚开始的时候,我把预训练层和全连接层的学习率都设为1e-5,效果非常差。后来看网上文章,才发现这两个学习率不用必须一样,未训练的层肯定要有更大的学习率。下图的函数就是把学习率精确到每一层。对于bias和Norm层不要权重衰减,全连接层的学习率调大到1e-2。
1 2 3 4 5 6 7 8 9 10 11 12 13 def get_group_parameters (model ):list (model.named_parameters())'bias' ,'LayerNorm' , 'batchnorm' ]'linear1' , 'linear2' ]'params' :[p for n,p in params if not any (nd in n for nd in no_main)],'weight_decay' :1e-2 ,'lr' :1e-5 },'params' :[p for n,p in params if not any (nd in n for nd in other) and any (nd in n for nd in no_decay) ],'weight_decay' :0 ,'lr' :1e-5 },'params' :[p for n,p in params if any (nd in n for nd in other) and any (nd in n for nd in no_decay) ],'weight_decay' :0 ,'lr' :1e-2 },'params' :[p for n,p in params if any (nd in n for nd in other) and not any (nd in n for nd in no_decay) ],'weight_decay' :1e-2 ,'lr' :1e-2 },return param_group
梯度累积
这个名词之前也听过但不以为意。直到这次batch_size实在太小了(在实验室10GB的卡上,batchsize只能为2,而且还不能用AdamW,只能用SGD;在kaggle的16GB的卡上也只能batchsize=4)。batchsize小的缺点是,容易震荡,模型每次反向传播的时候只能学到小batch的东西,导致梯度下降的方向反复横跳。梯度累积就是为这个而生的,每次计算梯度,先不要反向传播,等到累积到一定步数再计算平均梯度再传播,效果相当于一个大的batchsize。当然梯度累积也不能完全解决小batch的问题,例如batchnorm在小batch上肯定效果不好。
训练函数
以前的版本找不到了,用一个一折的版本
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 batch_size = 4 10 1e-5 80 'val' )True )1 , collate_fn=collate)2 , 4 , 6 , 8 ], gamma=0.4 ) 0 2e5 200 for epoch in range (epoch_num):0 for i, (X, y) in enumerate (train_loader):if (i + 1 ) % accumulate_steps == 0 or (i + 1 ) == len (train_loader):if (i + 1 ) % (accumulate_steps * 8 ) == 0 or (i + 1 ) == len (train_loader): print (f'the {epoch} th: {100 * (i + 1 ) / len (train_loader)} %' )0 eval ()1 None None for i,(X, y) in enumerate (val_loader):with torch.no_grad():if i == 0 :else :print (f'mse: {mse} .' )if mse < min_mse:'model' : net.state_dict()}, f'./minmse_fold.pth' )if lo < min_lo:'model' : net.state_dict()}, f'./minloss_fold.pth' )print (f'{epoch} th epoch: last loss: {lo * accumulate_steps} .' )if mse < min_mse:'model' : net.state_dict()}, f'./minmse_fold.pth' )'model' : net.state_dict()}, f'./last_fold.pth' )print (f'End.' )
训练结果
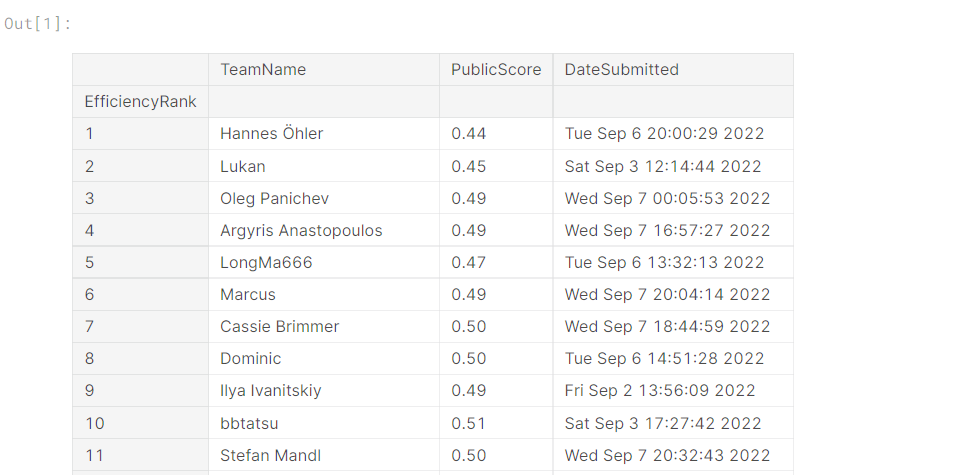
原始数据已经遗失了,在26%测试集上是0.47的结果,在当天排200多名,现在已经掉到300多了。
然后0.47在CPU上的排名,最高排过前5哈哈。不知道这个赛道有没有发奖牌的呢?还是只有前三名有钱啊qaq。
不足与展望
不足
1.数据少
2.六个维度一起训练,肯定不太可能达到很好
3.使用roberta。deberta-large我老是显存溢出,使用半精度训练效果很一般。
4.我还没空十折交叉训练,也没空跑几个不同的种子。
5.batchnorm到底有没有用也难说
展望
CPU和GPU肯定要有不同的方向。
CPU的话,2肯定改进不了了,打算从数据增强入手。
GPU的话,应着重改善2。
可能可以先在GPU训练6个单独的比较好的网络,然后用伪标签训练来反哺CPU的网络。