defedits1(word, typ = "nohalf"): """ 返回跟输入单词是1距离的单词 """ # 26个英文字母 ord():获取'a'的码 chr():通过码还原对应的字符 t = [chr(ord('a') + i) for i inrange(26)] t.extend([chr(ord('A') + i) for i inrange(26)]) alphabet = ''.join(t) if typ == 'half': alphabet = ''.join([chr(ord("'"))]) defsplits(word): """ 分割单词 以cta为例: ("","cat") ("c","at") ("ca","") ("cat","") """ return [(word[:i], word[i:]) for i inrange(len(word) + 1)]
# 分割好的单词 pairs = splits(word)
deletes = [] transposes = []
if typ != 'half': # 删除某个字符 deletes = [a + b[1:] for (a, b) in pairs if b] # 两个字符换位置 transposes = [a + b[1] + b[0] + b[2:] for (a, b) in pairs iflen(b) > 1] # 替换某个字符 replaces = [a + c + b[1:] for (a, b) in pairs for c in alphabet if b] # 插入某个字符 inserts = [a + c + b for (a, b) in pairs for c in alphabet] # 返回集合 returnset(deletes + transposes + replaces + inserts)
import contextlib defget_error_words(sen): """ 返回错误单词的二元组的列表:(错误, 正确) """ chkr = SpellChecker("en_US") #引入语料库 chkr.set_text(sen) #检查单词 err_list = [] for err in chkr: correct_list = chkr.suggest(err.word) a = edits1(err.word, 'half') #相差一个单引号 b = edits1(err.word) #编辑距离为1 edits1_list = [] perfect = False for word in correct_list: if word in a: err_list.append((err.word, word)) perfect = True break if word in b: edits1_list.append(word) ifnot perfect: if edits1_list: err_list.append((err.word, edits1_list[0])) else: with contextlib.suppress(Exception): err_list.append((err.word, correct_list[0])) return err_list
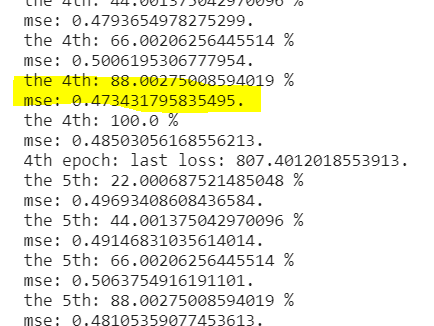
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
defcorrect(word): a = random.uniform(0, 1) if a <= 0.15: return word[0] #15%的概率消除空格 elif0.15 < a <= 0.25: return word + '\n\n'#10%的概率增加换行 else: return word #其余不变 defcorrect_match(match): word = match.group() return correct(word) defcorrect_text(text): """ 对符号后的空格进行是否删除 """ return re.sub('[,.?!] ', correct_match, text)