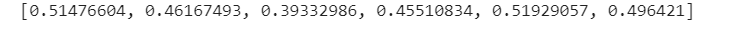前文提到了多个维度一同训练的弊端,包括数据增强的难处,以及不同维度相互牵制使得性能下降。本文单独处理了cohesion看看效果(由于batchsize无法很大,把batchnorm换成了dropout),效果印证了前文的猜测。
cohesion是什么?
说实话,只看英文翻译根本看不出来cohesion到底想要评什么分。
然后在网上查了一下,发现雅思有这个评分标准:
雅思写作评分标准之Cohesion(上)-明衔接 - 知乎 (zhihu.com)
大概意思是链接顺畅,连接词合理,使用代词,名词替换合理(最后这个我在实验前没看仔细,所以后文的处理方法有一丢丢小问题qaq,但是效果有提升就是了)。
数据增强
依照这个思路,理出数据增强的方法:
1.适当破坏或替换动词和名词(其实!正确方法应该是针对动词就行了,因为cohesion和连接词主要是副词、名词和代词都有关系!)
2.以句子为单位的窗口滑动,但要保证窗口不过于小以至于评分不匹配。
代码
简单地以段落为单位EDA一下:
1 2 3 4 5 6 7 8 9 10 11 12 import pandas as pd'./train.csv' )3750 ]import rer'\n\n' "full_text" ].map (lambda x : len (re.findall(rx, x)) + 1 )print (df.mean())print (df.median())print (df.min ())print (df.max ())print (df[df>18 ].count())
老规矩,看一下主代码先:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 for i in range (3750 ):if (i + 1 ) % 100 == 0 :print (i)'full_text' ][i].strip()for j in range (4 ): if paragraph_count >= 11 :elif sen_count >= 18 :" " ) len (li)for _ in range (length // 10 ): while True :range (length))0 ][1 ] if pos[0 ] in ["V" , "N" ]:0 , 1 ) if p > 0.5 : pass elif p > 0.3 : else :try :except Exception:break " " .join(li)len (data)] = data.loc[i]'full_text' ][len (data)-1 ] = textprint ("Finish." )
各函数如下(编辑距离为1的函数不表,前文已经提到):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 import randomdef get_paragraph_count (txt ):return len (re.findall("\n\n" , txt)) + 1 def get_seg_para (txt, index ):"\n\n" )if len (li) <= 18 : len (li) - 5 ) // 3 len (li) - 3 * seg_size - 5 if index == 3 else 0 return "\n\n" .join(li[seg_size * index + delta : seg_size * index + 5 + delta])else : len (li) // 4 len (li) % 4 if index == 3 else 0 return "\n\n" .join(li[seg_size * index : seg_size * (index + 1 ) + delta])def get_sen_count (txt ):return len (re.findall(r'[.!?]' , txt))def get_random_sen (txt ):'[.!?]' , txt)len (li)0 0 while b - a <= l // 4 : 0 , l)0 , l)if a > b:return ". " .join(li[a:b])
同义词(nltk这个库真的有点好用,虽然老是得手动下载一些语料库):
1 2 3 4 5 6 7 8 import nltkfrom nltk.corpus import wordnetdef get_synonyms (word ):for syn in wordnet.synsets(word):for lm in syn.lemmas())return random.choice(list (set (synonyms)))
实验效果的对比
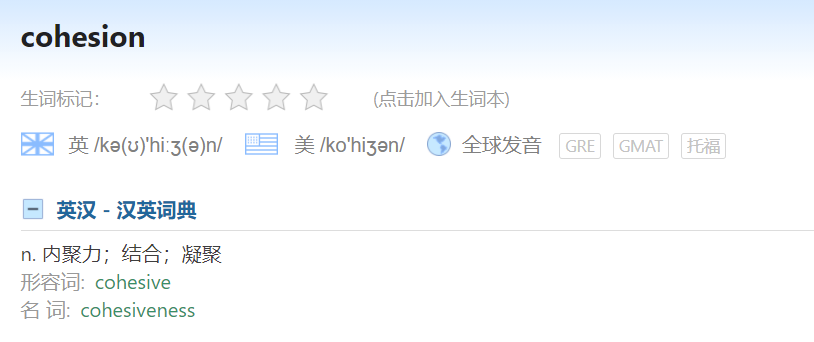
首先,先来看一下之前六个维度训练时,cohesion维度的效果:
可以看到0.51476604,这个维度拖后腿比较严重(也验证了我说相互牵制的预测,cohesion比较看重上下文)。
然后roberta-base单独训练,不使用增强数据时,降到了0.50多(忘了截图了),还是挺好的
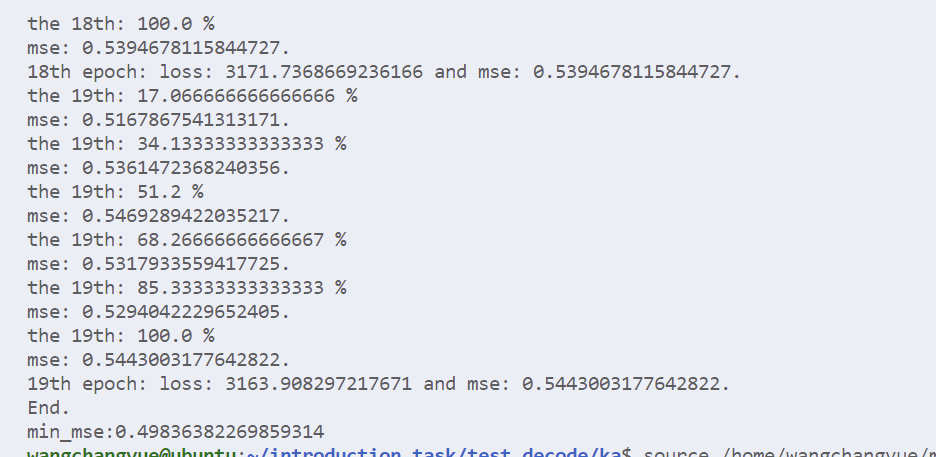
使用增强数据后,又到了0.5-了:
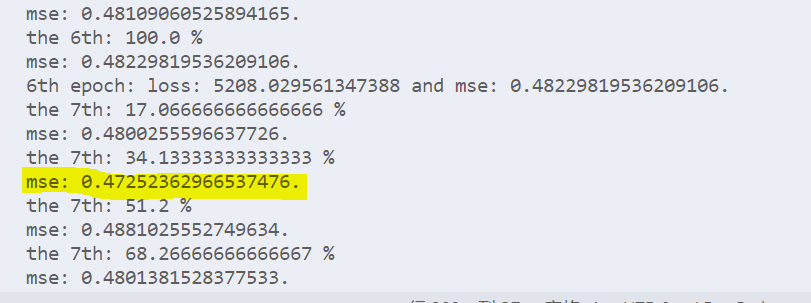
然后我还用deberta-base+增强数据训练了一下,不得不说deberta确实是yyds哈,这下已经到了0.472了(截至发文还没训练完):
四个点的增强还是很舒服的。