分层是为了防止整体把某些因果作用掩盖了。配对,例如双胞胎,是分层的特例,分得特别细。
分层随机化试验
重点是Neyman和回归方法
记号
j是分层的某一层,例如16个学校。
Nc(j)和Nt(j)分别是第j层的控制组个数和处理组个数、
倾向得分:e(j)=N(j)Nt(j)
分层的比例:q(j)=N(j)/N(横向的比较)
满足无混杂假设:P(W∣X,Y)=P(W)
本课考虑分两层的情况:

Fisher方法下,如何填补?
Is Tdif=∣Ytˉobs−Ycˉobs∣ still valid?
Yes. 理论上可以得到真分布,是对W的重排。Fisher方法用什么统计量都可以(
Is Ytˉobs−Ycˉobs still unbiased?
No。取决于倾向得分。
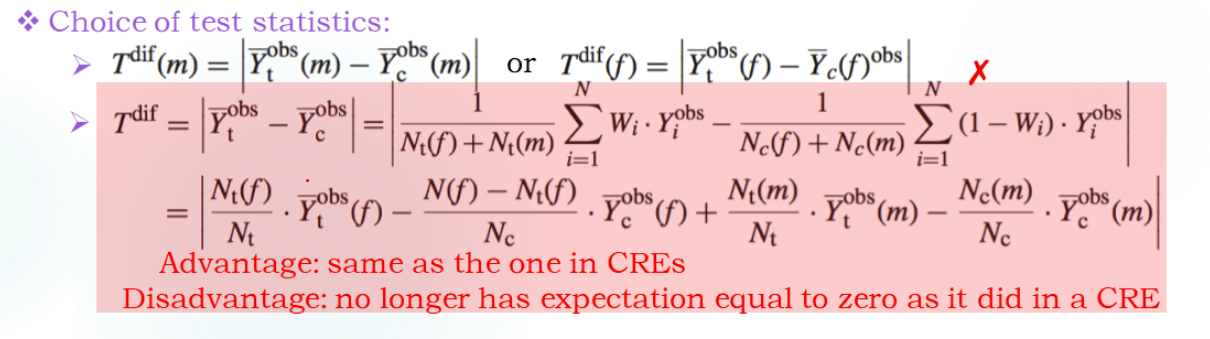

加权的计算是可以的,而如果使用秩也需要加权:

Neyman方法


SREs vs CREs
| W(竖表)X(横表) |
f |
m |
| 0 |
Nc(f) |
Nc(m) |
| 1 |
Nt(f) |
Nt(m) |
q=N(f)/N
假设e(j)=Nt(j)/N(j)=p=Nt/N

σt2=Var(Yi(1))=E[Var(Yi(1)∣X)]+Var[E(Yi(1)∣X)]
CRE到SRE,精度提高了(方差变小了)。从图中式子可以看到,不同组之间的差异越大,分组的效果越好。也就是说无论协变量分层有没有用,精度至少不会降低。(但也不是说一味地添加协变量越好,因为实际上方差是要估计的,分层越细样本量越小)
精确的计算**( 要求掌握,复习的时候注意推一下 )**(见下方):
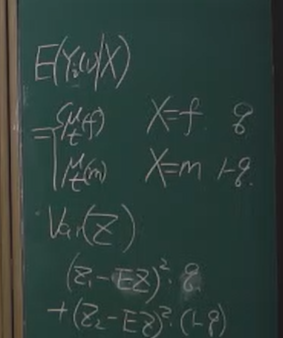
两点分布(设X=1为男,X=0为女)的特性得到:
Var[E(Yi(1)∣X)]=Var[Xμt(f)+(1−X)μt(m)]=Var[X(μt(f)−μt(m))]=q(1−q)[μt(f)−μt(m)]2
E[Var(Yi(1)∣X)]=qσt2(f)+(1−q)σt2(m)
故:
σt2=qσt2(f)+(1−q)σt2(m)+q(1−q)[μt(f)−μt(m)]2
所以:
NVsp(τ^dif)=N(Ncσc2+Ntσt2)=1−pσc2+pσt2
和NVsp(τ^strat)相减就可以消去很多项。
回归方法
β(j)是第j层的截距。用了截距可以不同,斜率要相同的回归模型。

w(j)是每一层的精确程度,加权起来是τw。
另一种斜率不同的模型,可以理解为每一层先回归,再加权平均。或者把τ显式地拆开。

Model Based方法

让参数取决于新的参数(超参数)。
配对随机化试验
认为一对内的差异远远小于对间的差异。当样本量比较大的时候,认为能找到比较相近的个体。
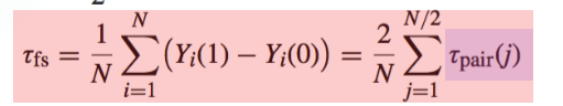
Which method can we apply straightforward?
FEP & Model-based Analysis.
主要就是其他两个要求样本量。
Fisher方法
和分层一致
Neyman方法

层内小样本的问题。
解决方法是加假设,捏合的思想:


回归方法
类似Neyman的思想。

