理论上,哪种研究必须考察协变量的混杂性?
- RE
- OBS
答案:是只有OBS。问题的意思是找到某些X使得在X下W和Y独立,而随机试验中W已经是随机分配的了,已经是和Y独立了。
Design
是在看到Y之前进行的。研究W的分布。
Goal:Valid Inference
Rule:1)Inference Precision:higher、better
2)Valid Range:longer、better
下面三步是一个循环。
0.估计倾向得分
见上节课。
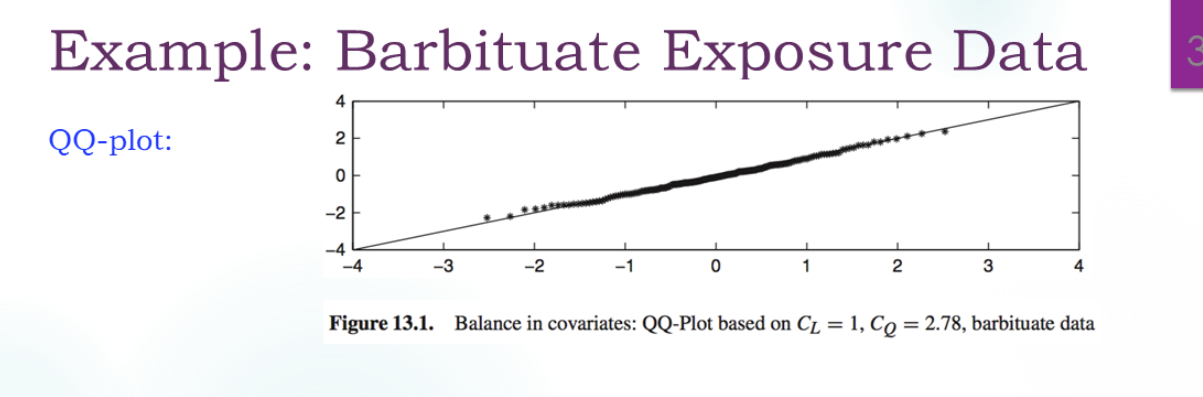
1.Assessing Covariate Balance
How difference are the two distribution?
- 单变量Xi的比较(这里的X应该指的是某一个维度的协变量)(优点:model free):


-
总体X的比较,马氏距离(倾向得分本身就体现了协变量的重要性差异,依赖倾向得分的估计,这部分是model的):


p=EWi=P(Wi=1)P(Wi=1∣Xi=x)=E(Wi∣Xi=x)=e(x)所以p=E(e(x))

ftE(e)=f(e(X)=e∣Wi=1)
由上节课知道在e(X)下,W和X是独立的。
所以P(Wi=1∣e(Xi)=e)=P(Wi=1∣e(Xi)=e,Xi=x)=P(Wi=1∣Xi=x)=e(x)=e
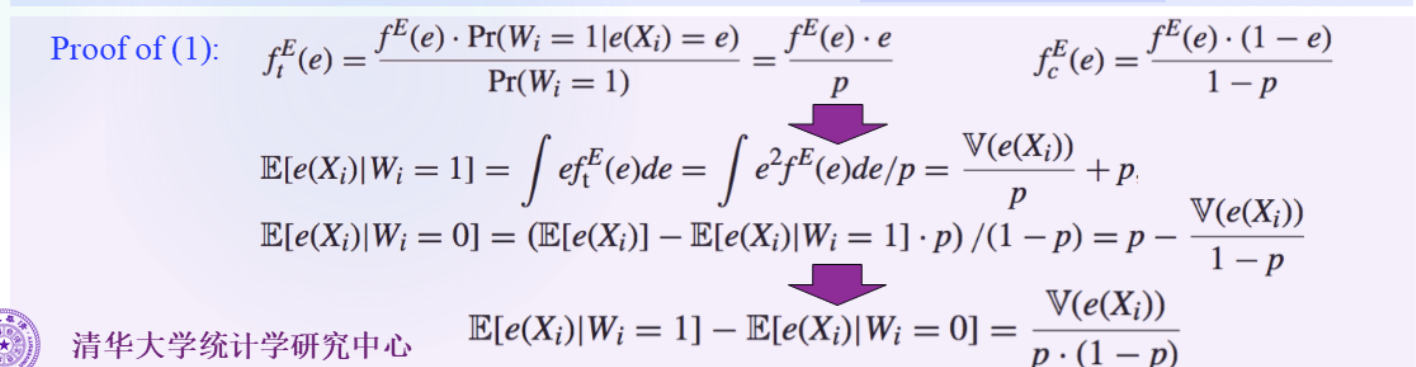
由上面的引理得到:

Whether exists similar units?
能不能找到对照?

可能要考虑舍弃一些数据。
2.Improving Balance
如果评估失败,需要平衡。
Trimming
修整:

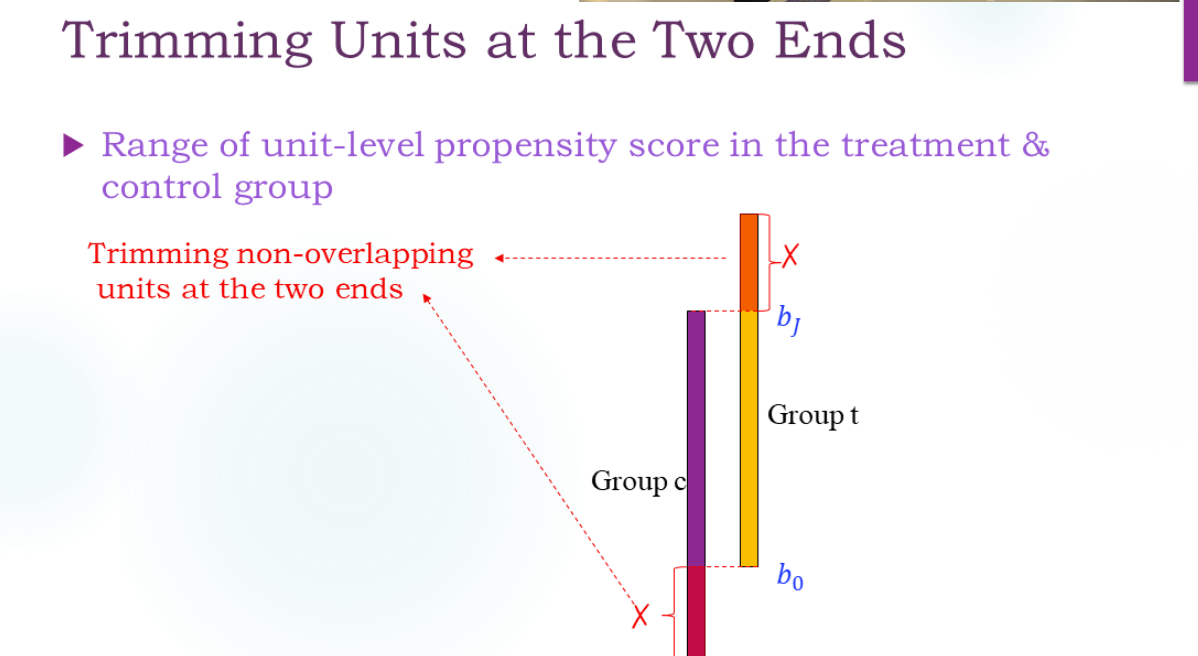
注意这里的倾向得分计算是用那个逻辑回归模型估计的,输入X得到倾向得分。
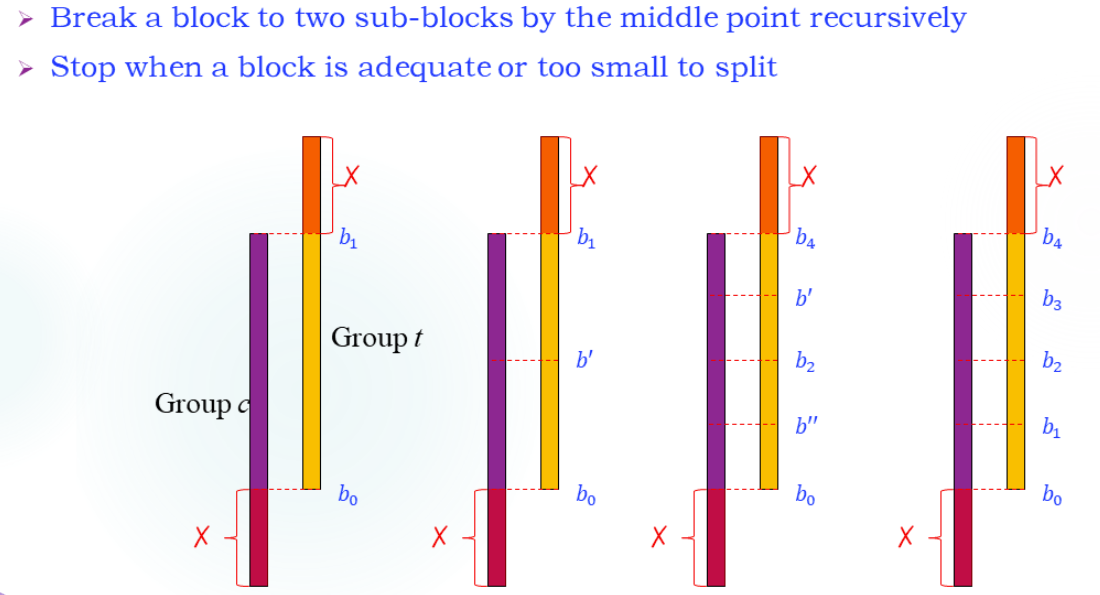
Blocking
Trimming切完之后内部也可能不均衡
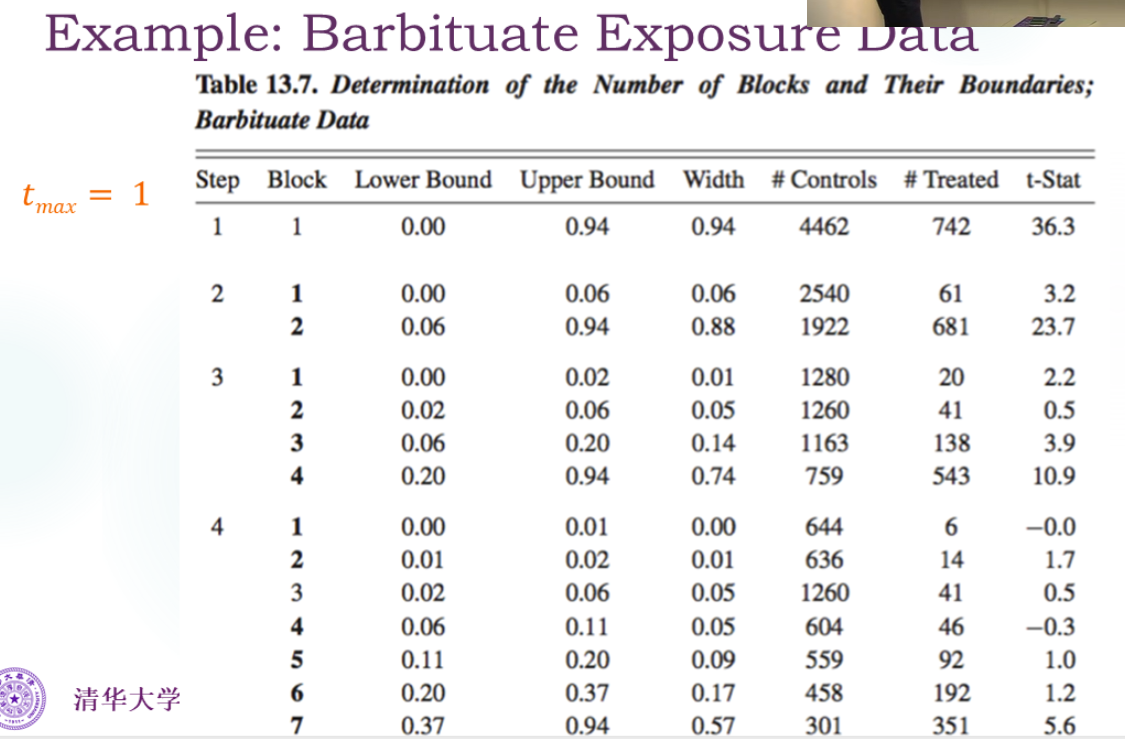



Matching
找1个相似还是M个相似,选择过程是不是无放回?(即,已经被选走的能不能被别人选走)。

Analysis
Analysis based on Blocking
blocking处理后估计的结果是不是无偏的?
期望
关心E(τ^dif−τfs∣X)是否为0。(简化了,不是τsp)

第一步第一项哪来的:
E(Nt1i=1∑NWiYi(1)−N1i=1∑NYi(1)∣X)=E[E(Nt1i=1∑NWiYi(1)−N1i=1∑NYi(1)∣X,W)]=E(Nt1i=1∑NWiYi(1)−N1i=1∑NYi(1)∣X,Wi=1)P(Wi=1)+E(Nt1i=1∑NWiYi(1)−N1i=1∑NYi(1)∣X,Wi=0)P(Wi=0)
上式的第一项:
=E(Nt1i=1∑NYi(1)−N1i=1∑NYi(1)∣X)⋅NNt=E(Nt1i=1∑NYi(1)−N1i=1∑NYi(1)∣Xi)⋅NNt=NtNNci=1∑NE(Yi(1)∣Xi)⋅NNt=NNcE(Yi(1)∣Xi)
第二项就比较容易算了。
结果有偏(完全随机化试验下结果也一样,但这个平均差是0,所以无偏)。
分层后:

线性模型假定下:


如果真实模型不是线性模型,使用回归法调整是否还有帮助?
是。如果是高阶的ΔY=f(ΔX),也能用Taylor展开。
方差


引入回归,不仅可以减少偏差,还能减少方差。(因为ε拆出了Xβ出来)

和Weighting方法的比较

也就是说Blocking是更粗的Weighting方法,用所在层的平均倾向得分e(j)来代替,而不是个体的倾向得分。
Blocking的优点就是更稳定,而Weighting是无偏的。
Analysis base on Matching

配对的顺序、配对的度量方法是很有影响的。
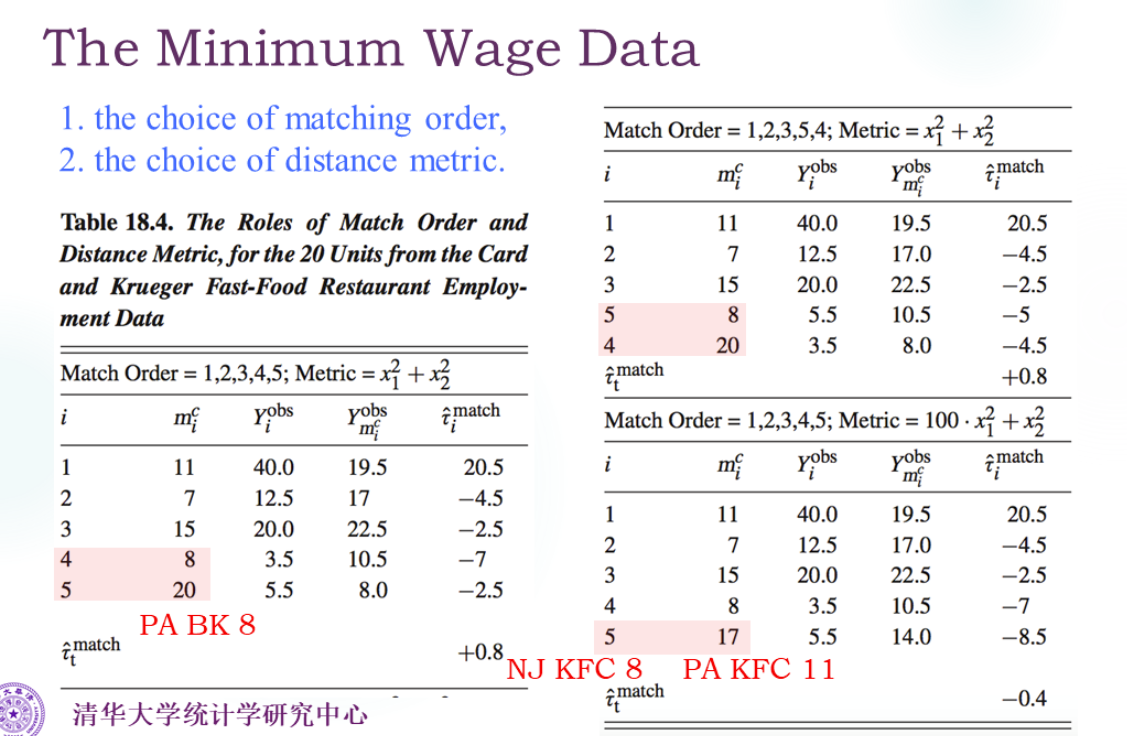
有放回的匹配:
偏差会变小,方差会变大。

反过来就是


