论文阅读笔记 非自回归模型综述
| 题目 | A Survey on Non-Autoregressive Generation for Neural Machine Translation and Beyond |
|---|---|
| 论文链接 | https://arxiv.org/pdf/2204.09269.pdf |
| 作者列表 | Yisheng Xiao*, Lijun Wu*, Junliang Guo, Juntao Li, Min Zhang, Tao Qin, Senior Member, IEEE and Tie-Yan Liu, Fellow, IEEE |
| 作者单位 | 微软亚研院,苏州大学 |
| 文章类型 | 长文 |
简介
非自回归(NAR)生成首先用于加速翻译,称为NAT模型,缓解AT模型O(n)复杂度的问题,但这是以精度为代价的。
文章outline:
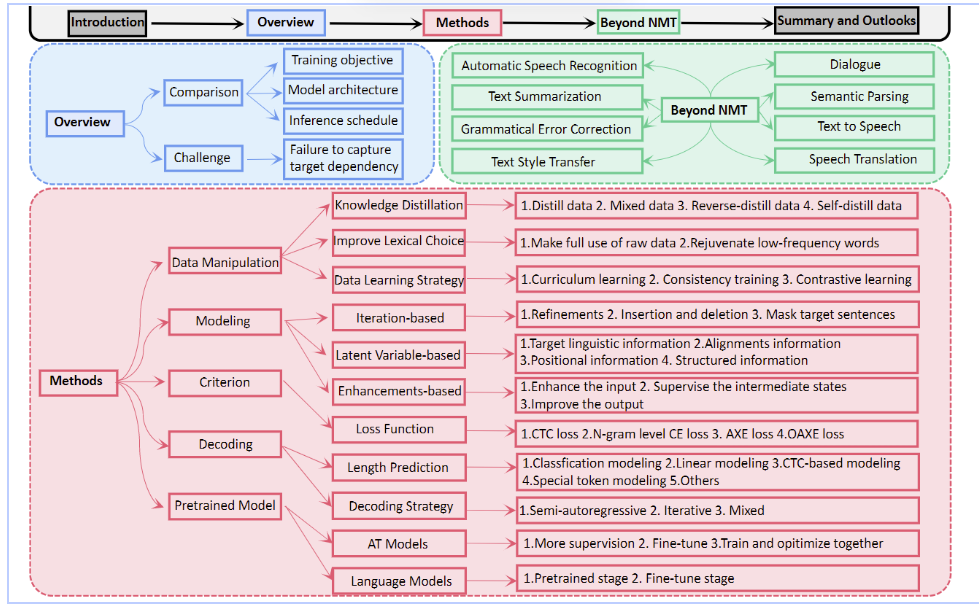
总览
优化目标
AT模型的优化目标:
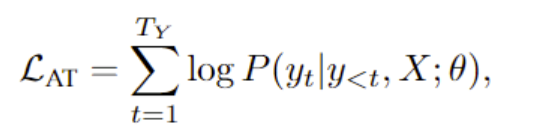
(完全的)NAT模型的优化目标:
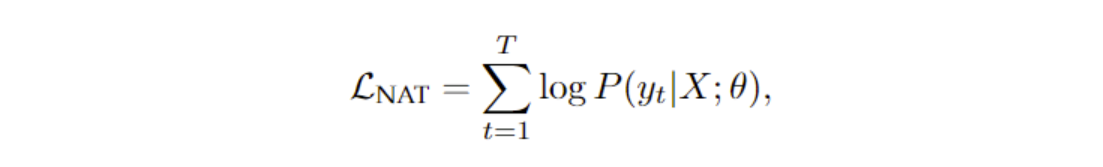
区别有二:第t个token的解码不取决于y<t的序列,且在推理阶段,句子长度T是需要预测的。
半自回归SAT模型的优化目标:
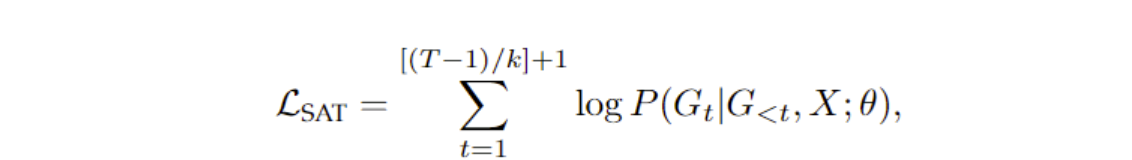
其中k是在一个时间步上并行生成的token数量。当k=1和k=T时,退化为AT和NAT模型。
基于迭代的NAT模型优化目标:
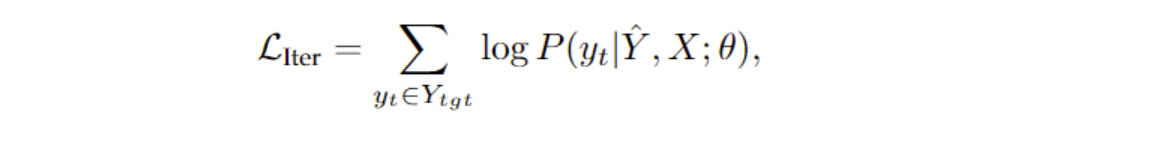
每一步的解码以上一步的生成句子为基础,继续优化。
模型架构
编码器基本没区别,主要是解码器。
NAT模型在训练时不再需要掩码矩阵。当然SAT模型仍然需要掩盖后续组的token。
主要挑战
NAT模型最关键的问题是,编码器的输入只能依赖源端的信息,作者称之为:“fail to capture the target dependency of target tokens”。
这会导致以下问题:
- 每一个target token都是独立预测的,模型可能选择不同合理翻译的错误组合,导致错误。
- 过度翻译和翻译不足,就是source token某些被翻译了多次,某些没被翻译到。
改进方法
- 训练数据改进
- 模型层面的改进
- 训练目标改进
- 解码策略的改进
- 借助预训练模型
数据改进
知识蒸馏(KD)
先用AT模型对训练集的句子解码得到目标句子,可以用贪婪、束搜索等方法,然后得到蒸馏后的数据集,用传统的负对数似然损失对NAT训练。
但是也发现不是更好的教师模型能教出更好的学生模型,他们的能力应该保持一致。知识蒸馏的优点是减少预测目标的依赖性、减少词汇多样性和token重排程度,有利于NAT学习source和target的对齐。
缺点是低频词的翻译准确性会降低,也有一些处理方法。
数据学习策略
主要是课程式学习,从难到易的学习。例如逐步将解码器的输入从AT模式切换到NAT模式。例如在训练的时候,对于decoder输入,第一步先用encoder输入,之后计算decoder输出和golden truth的距离,在golden truth中随机采样(采样数正比于距离)替代上一次的decoder输入,这样可以根据模型的能力逐步调整学习片段。另外还有从单词、短语、句子级别的课程式学习等等。
模型改进
基于迭代
插入和删除
基于平衡二叉树的生成顺序,就是同时预测位置和token,再预测子树的单词,就是insertion-transformer。也有基于删除的操作。
掩码和预测
在推理时,每次迭代时低预测概率的token会被mask以供下一次迭代。这种mask的选择也有改进工作:如源句子相应的oken也被联合掩盖;使用自回归的解码器(和原来的解码器共享参数)来预测需要mask的token;使用更高级的策略选择mask等。
基于潜变量
引入了潜变量Z,似然变为:
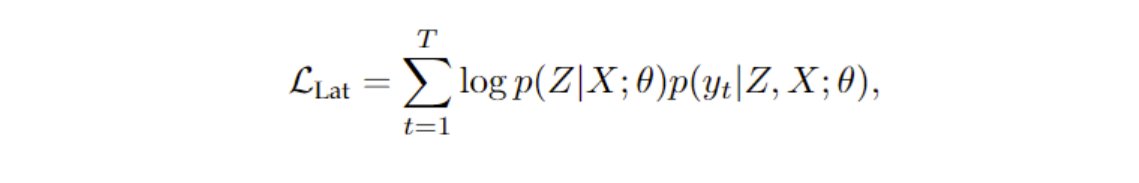
也就是先生成潜变量,再生成句子。其实就是decoder的输入如何优化。
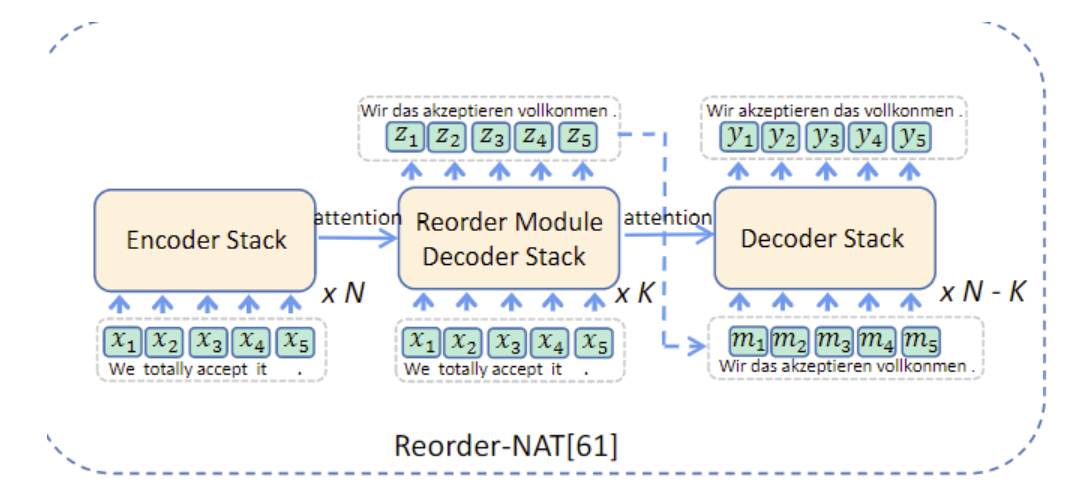
文章简单介绍了很多方法,没办法一篇篇点进去看,下面两种是有图的:
第一种就是利用对齐信息,decoder的输入不再是简单的encoder输入,而是预测encoder输入中哪些单词如何与target对齐,再以此为decoder输入。
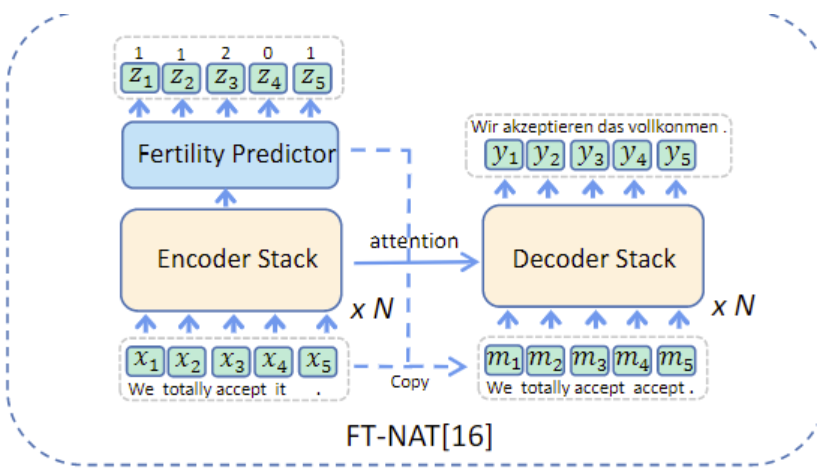
第二种就是重排,这个图有错误的,Reorder的输出是伪翻译,即source语言,但是顺序是以target语言为基础。
其他
- 使用短语表查找和嵌入映射,作为decoder的输入,使得其更接近目标句子
- 对中间状态进行监督。例如使用额外的注意力块来增强decoder层之间、以及生成句子的邻居token之间的关系。
- 对解码器的输出改进,例如惩罚相似的hidden state等,没有点进文章细看。
训练目标
最基础的是交叉熵
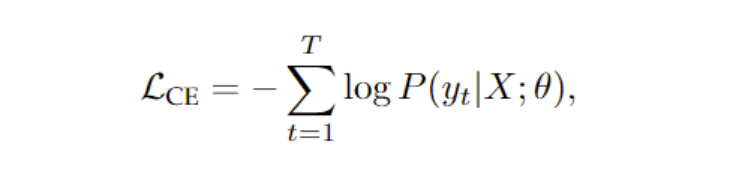
问题就是正确翻译的顺序可能有多种,而NAT预测的token没有相互依赖,交叉熵会惩罚那些正确翻译但顺序和golden truth不一致的翻译。
所以改成基于N-gram的损失函数。
另外CTC和基于顺序的损失函数就似懂非懂,干看综述里是很不详细的,要点进去细看要花很久,所以没有看。
解码
长度预测
NAT必须事先预测句子的长度,有以下方法:1. 建模长度预测为分类任务;2. 建模为线性回归;3. 引入[LENGTH]标记直接得到长度预测;4. 基于CTC的建模
改进的方法有:在预测长度后,选择一个范围而不是只使用这个长度,用这个范围预测并采用最佳翻译;或者直接预测多个可能的长度。
解码策略
半自回归解码
基于语法标签:生成语法参考树,一个步骤解码一组有语法关系的token
恢复机制:分段生成,每个段中的token是自回归生成的,基于当前所有已生成的token(包括其他段),引入DEL标记以删除重复的段。每个段起始都是BOS,直至遇到EOS或DEL停止。
Aggressive decoding:先用NAT生成草稿,然后用AT模型验证(验证时使用一些准则,如:在AT模型预测的top1位置,或者在AT模型预测的topk内且对数似然的差值在一定范围内),找到第一个不符合AT模型验证的token,把后面去掉,重新让NAT预测后面的句子。反复迭代。
迭代解码
掩码预测(上文已经介绍,有easy-first等)、插入和删除、重写机制(带修改器和定位器的机制,定位器用于确定哪个单词要保留/修改,需要修改的mask掉让修改器预测;还有一个应用波束搜索的,看不太懂)
混合解码
例如Diformer可以在推断时(每个时间步)动态选择L2R、R2L或迭代式NAR解码。
利用预训练模型
- 使用AT监督训练:这些方法大致是要求训练时NAT隐藏层的状态也向AT模型靠拢。
- 上文提到的课程式训练
- 联合AT模型一起训练:1. 用NAT模型的输出迭代更新AT,用AT的新输出训练NAT模型;2. 共享encoder,然后一起训练,一起计算损失。
NMT外的任务
我只看了摘要的任务,和NMT相比优势是目标句子的信息已经显式或隐式地在长文本输入中了。只有一篇论文:https://arxiv.org/abs/2205.14521,感觉有点复杂还没细看。
发展趋势
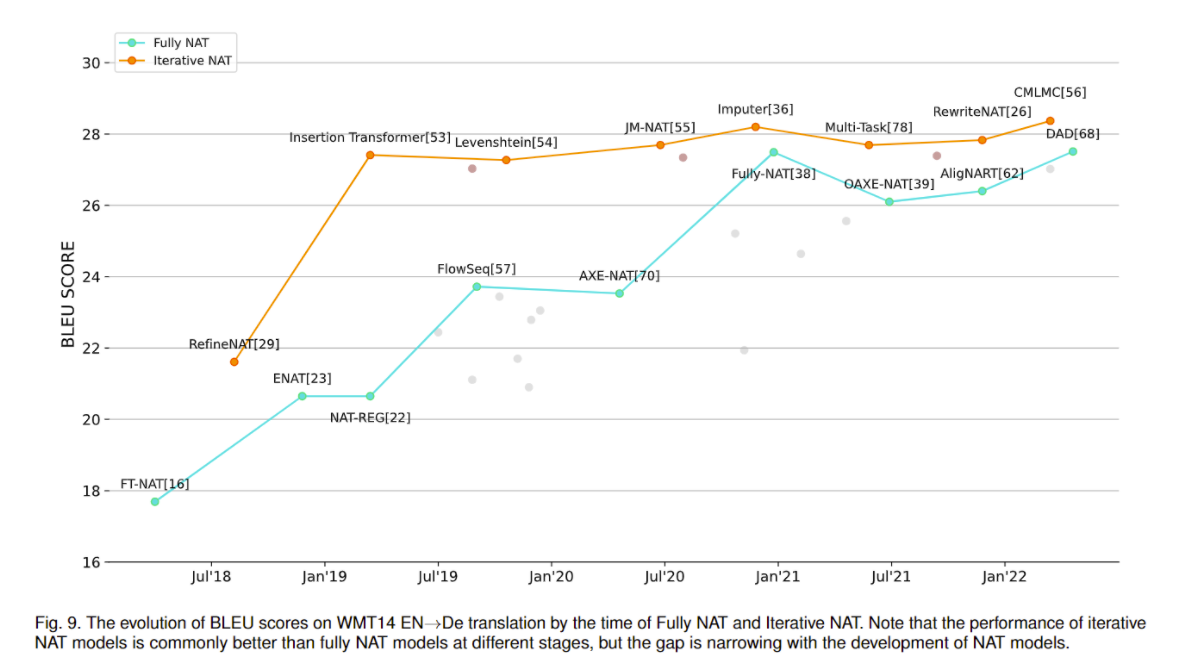
可以看到完全NAT已经越来越好了,快赶上迭代了。