论文阅读笔记 第一阶段检索综述-上篇
看这篇综述主要是一个入门的学习,所以最后加上一些论文外的笔记补充。
没有写得很详细,主要想了解整个的历史框架。
文章太长了,分两次记录。
| 题目 | Semantic Models for the First-stage Retrieval: A Comprehensive Review |
|---|---|
| 论文链接 | https://arxiv.org/abs/2103.04831 |
| 作者单位 | 中科院,阿里巴巴 |
| 文章类型 | 长文 |
简介
主要是关于Large-scale query-document retrieval的,从给定的大型文档库中返回一组相关文档。现代检索系统一般采用多阶段排序:粗筛和重排。如下图:
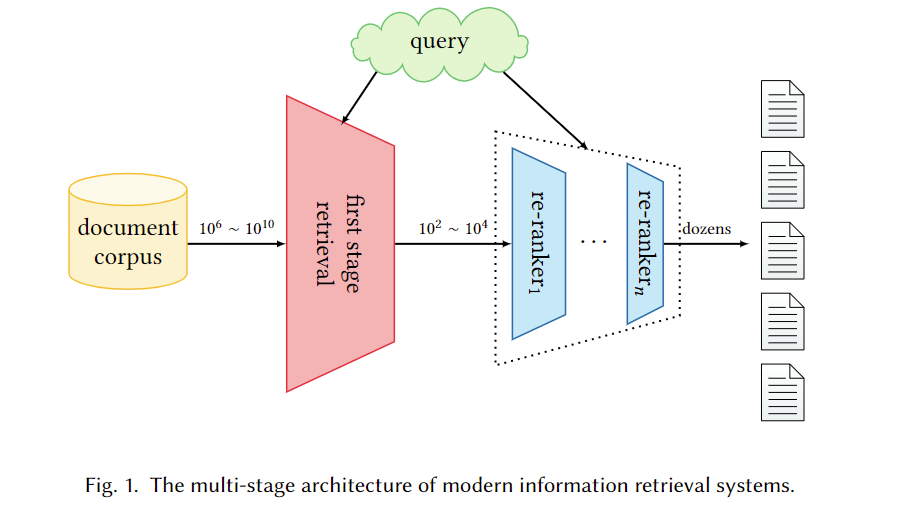
其中第一阶段的目标是高召回率、高速度。重排则可以使用计算上更昂贵的模型。第一阶段检索长期以来由基于术语(term-based model)的经典模型主导,使用词袋技术和倒排索引,缺点就是忽略了顺序、独立性假设。有很多传统的改进工作,但都是离散的表示范式。
单词嵌入和深度学习的发展刺激了第一阶段检索的发展。本文主要关注第一阶段检索的语义模型,利用语义信息来完成第一阶段检索是必要的。
第一阶段检索的运用场景
ad-hoc retrieval
大概是doc相对静态,而query持续地提交这种任务。主要特征是query和doc长度差异很大。旨在返回排序好的列表。
OpenQA
旨在提取文本片段作为问题的答案。包含检索阶段和读取文本阶段。检索阶段就运用了第一阶段检索。
Comunity-based QA
使用已有的问答对来回答用户的问题。有两种方式产生返回给用户的答案:1.从答案中检索;2.选择重复的问题,把其答案作为结果。后者需要捕获单词间的语义相似性,前者要捕获答案和问题之间的逻辑关系。
背景
模型公式化

大致意思是s(·, ·)就是要训练的模型,给出q-d对之间的打分。
Φ是query的嵌入映射(在线计算,需要高效,和φ可以相同也可以不同,取决于搜索任务),φ是document的嵌入映射(独立于q,因为在部署搜索系统的时候不知道查询是什么,这就说明文档的嵌入表示的计算可以是离线的)。
f评分函数应该简单,因为是在线计算的,且需要考虑索引技术。
索引技术
有签名、倒排索引、密集矢量索引等,文中介绍了倒排索引和密集矢量索引。
倒排索引
对于query中的每一个词(每一项?),在倒排索引中查找,词在某个文档出现的次数会增加这个文档的评分,最后返回累计评分topk的文档。当然有很多加速策略,有时间研究。
密集矢量索引
倒排索引适合词语矩阵稀疏(我的理解是一个term对应的document list不多)的文档集合,为了解决密集的文档,使用表示学习、近似最近邻搜索算法。计算完query和document的嵌入后,最近邻搜索即可。当然实践上使用的是近似算法,有基于树、哈希、量化(?quantization)、图(proximity graph)的方法。有时间研究。
经典的Term-based索引
都是基于词袋模型建立的向量,而式子(1)中的两个表示函数设置为手动定义的特征函数(如字频或表示向量的维度,保证了表示的稀疏性,可以使用倒排索引*(?这里有点不理解)*)
向量空间模型VSM
把经典词袋模型稍作修改,向量每一个维度的权重是不同函数,如词频、倒排文档频率、或它们的组合等,然后计算query向量和document向量的余弦相似度,就是评分。
概率方法
使用概率理论估计𝑃 (𝑦 = 1|𝑞, 𝑑),即query和document相关的概率。
最经典的是The Binary Independence Model (BIM),但它假设了词语是二元的(出现与不出现)、词语间独立,因此有树依赖模型、BM25模型来放宽这些假设。
IR的语言模型
估计,也就是为每个文档d建立一个语言模型,而这个语言模型建立在词袋模型之上。我自己去查了一个例子:
这个模型的思想是,需要计算的是,其中P(q)对所有d是一致的,可以省略,P(d)可以假设是一样的,也可以用阅读量、文章长度等等去构建评分。主要是计算P(q|d),相当于。
一个简单的想法是利用多项分布计算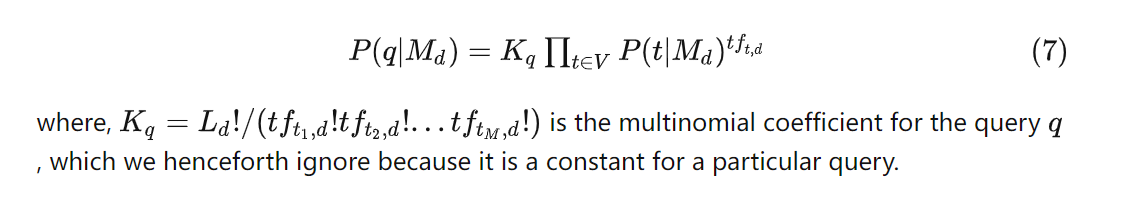
所以重点是估计,最简单的语言模型就假定词语间独立,也可以像人智导拼音输入法那样的二元马尔可夫假设。而估计可以像人智导那样平滑,或者其他方法。
这几种方法的优点是高效,缺点是无法捕捉语义。
早期的语义检索
Query扩展
向query中增加相关的term。
全局方法
使用词库(外部词库或该语料库的词库)来扩展或重新表述query中的单词,来提高平均检索性能,但这种提高不稳定。
局部方法
根据原始查询得到的文档,重新调整query。被称为伪相关性反馈PRF。对许多检索模型提高性能有效,且稳健。
Docunment扩展
补充倒排索引中每一列的内容。
Singhal和Pereira使用文档作为query进行查询,然后取得top10个文件,新的向量表示是这些文件的加权平均。本质是用聚类来确定相似文档。
缺点是当扩展技术改变,需要重新对语料库索引,代价高。
Term Dependency Models
旨在考虑term之间的依赖性(顺序?)。
一个方法是对于倒排索引,扩展出phrase维度,评分函数就是term级和phrase级的评分加权和。
但是这种直接提升n-gram中n的方法并没有很显著的效果提升,一些图的方法(马尔可夫随机场等)有更好的提升,这里不表(也没太看懂)。
Topic Models
使用主题这个概念代替term,这里无法使用倒排索引,因为主题不是稀疏的。
分为概率方法和非概率方法。非概率方法,通常使用矩阵分解,矩阵是document-term矩阵,分解得到主题的混合,概率方法中,使用生成模型,主题是词汇表中term的概率分布,文档是主题的概率分布。
自己的理解是大概是通过学习(或矩阵分解?或某些多元的东西,比如因子分解这些?总之这些都不是基于深度学习的)把representation投影降维,变得密集,再计算余弦相似度。或者把主题得分和term得分加权和。
这种方法有很多缺点,例如学习能力差、忽略查询和文档的异质性、term级别上丢失信息。
Translation Models
利用统计机器翻译SMT,将query和document视为文本的两种语言表达,需要有监督地学习q到d的翻译概率,而P(d|q)正比于P(q|d)P(d)。可以借助上述的IR的语言模型来理解。
和传统机器翻译的区别是,q和d是同一种语言,自翻译概率P(w|w)的计算要求精确,太大会影响其他概率,太小则影响精确匹配,有各种估计方法,这里不表。
总结:
综述里说得挺好,我直接把翻译贴过来。
早期的语义检索模型,如查询扩展、文档扩展、Term Dependency Models、Topic Models和Translation Models,旨在使用从外部资源或集合本身提取的语义单元来改进经典的词袋模型表示。它们中的大多数仍然遵循经典的基于term的方法,通过在符号空间中用高维稀疏向量表示文本,以便容易地与反向索引集成,从而支持高效检索。
然而,这些方法总是依赖手工制作的特性来构建表示函数。因此,只能捕获浅层的句法和语义信息。尽管如此,这些早期的方法至关重要,因为它们已经初步探索了第一阶段检索的有益因素。因此,当深度学习技术爆发时,可以启发一系列新的语义检索模型,并同时获得令人兴奋的结果。
神经方法
见下一篇。
自己的补充
词袋模型Bag-of-Words(BoW)
见Bag-of-words模型入门 - 知乎 (zhihu.com)
文档中每个单词的出现都是独立的,不依赖于其它单词是否出现、顺序无关的。
其实就是一个统计直方图,对于字典大小为N,每个文档都是一个N维向量,第i个位置的值代表字典中第i个单词在文档中的出现次数。
倒排索引
索引的一种(比如关系型数据库的B+数索引、哈希索引都是索引的一种)。根据属性的值来查找记录,例如储存某个单词在一个文档或一组文档中的位置。在搜索引擎中一般是记录关键词、频次、位置。
倒排索引的关键是实现时的保存和压缩技术等。