论文阅读笔记 第一阶段检索综述-下篇
接上篇。
语义检索的神经方法
早期的深度学习方法集中在rerank阶段,晚近几年开始在第一阶段检索有重大进展。
稀疏检索方法
用稀疏向量表示每个文档和每个查询,其中只有少量维度处于active状态。解释性更好。
稀疏检索很容易集成到倒排索引中,可以分为两类:
神经加权方案
在编码时和传统方法类似,但是在term加权评分时,使用神经方法。一种直接的方法是直接预测权重,另一种是用额外的term扩充每个文档,然后用基于term的经典方法来索引(?)。
预测权重的最早模型是DeepTR,用embedding来预测term的重要性,将每一个term的嵌入用回归方法投射到权重上,权重用于评分加权(看文章的意思也可能是在生成query的表示时的加权?)。近来的term discrimination values (TDVs)方法,利用FastText(一个简单快速的浅层神经网络文本分类器)替换倒排索引时的IDF字段,并且最小化document的词袋表示的L1范数,以减少倒排索引的内存占用(?为什么会)。还有人使用上述的翻译语言模型中的embedding,利用单词的嵌入来估计翻译的概率(相当于嵌入越相似,翻译概率越高),弥补了词汇不匹配的问题。
近年来的上下文词嵌入,比以前的静态嵌入(例如经典的Word2Vec)更有进步,所以有工作利用上下文词嵌入来估计加权。基于BERT的DeepCT模型,利用BERT输出的表示映射到term的权重,替换掉倒排索引的TF字段,能够很好地估计词的重要性。对于长文档的term权重,引入HDCT模型,先用BERT生成的表示来估计段落级的术语权重,然后把段落级权重加权和得到文档级权重(这个加权和的权重怎么来?)。
有的工作直接评估term和整个文档的分数。例如Mitra的工作,假设了query term的独立性,使用神经排名模型(如BERT),离线地计算所有词和每个文档之间的分数。在段落级的检索任务比传统方法有显著改进,而比普通的神经方法只差了一点。
除了显式预测权重,也有使用seq2seq模型来扩充文档。例如doc2query模型是训练出来的用doc生成query的模型,为每个文档生成几个query,附加在原始文档上,照常索引。docTTTTTquery模型,使用T5来生成query。
稀疏表示学习
直接学习φ和Φ函数,为q和d构建稀疏向量。学习的稀疏表示可以用于倒排索引,倒排索引表中每一单元代表一个“潜在单词”,而不是传统的term。
一种方法是,将query和document中的每个n-gram映射到低维密集向量,然后学习一个把n-gram表示转换为高维稀疏向量的函数,最后使用点积来计算query和document的相似度。但是n-gram只是局部信息,并不是全局的上下文信息。另外还有UHD-BERT模型。
密集检索方法
密集向量能更好地捕捉上下文信息。
通常使用如下的双编码器结构,学习的密集表示通常以近似最近邻算法ANN进行搜索:
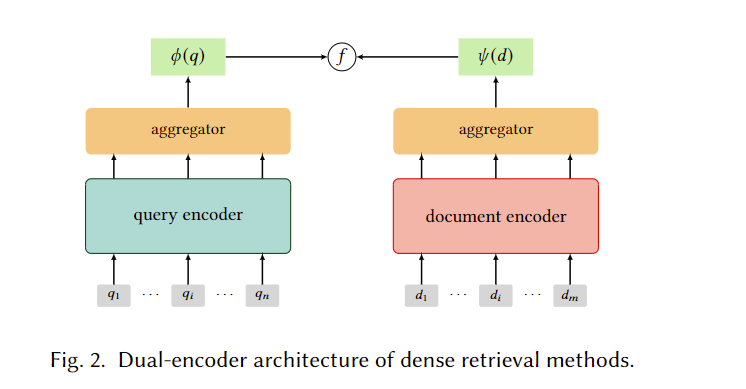
重要的是文档端的学习,密集检索方法可以分为term级和doc级:
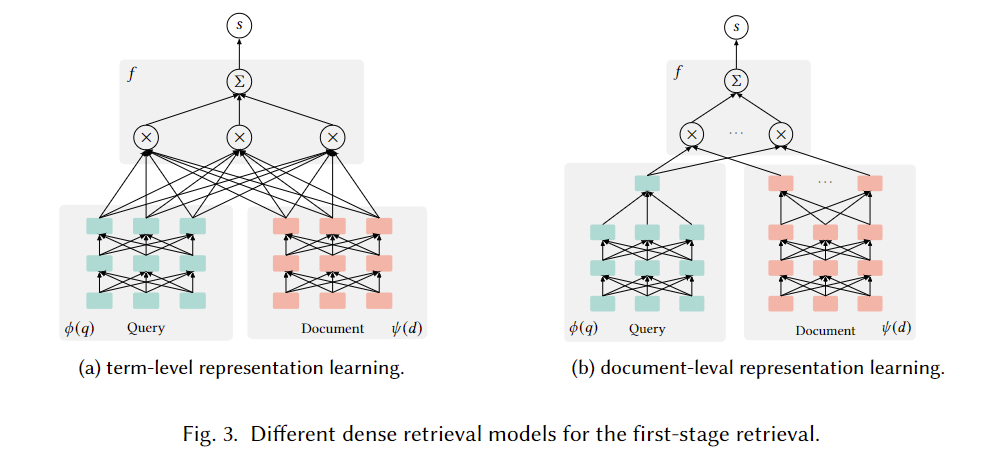
term-level
query和document都表示为term embedding的序列。
最简单的方法是采用词嵌入,更高级的方法有:在大型未标注查询语料库上训练一个word2vec,保留了输入和输出映射(这里很不理解,word2vec确实有两个矩阵,但是第二个矩阵是N*V维的,是将词向量投射到输出的,难道意思是把他转置或取伪逆???),在ranking阶段,将query词映射到输入空间,将文档词映射到输出空间,然后聚合q-d之间的余弦相似度,可以对返回的top文档进行rerank。
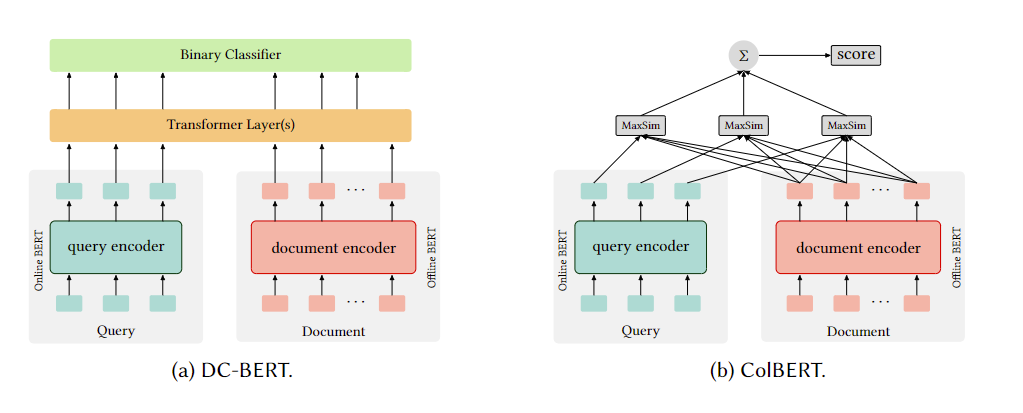
近来大模型的加入,例如DC-BERT和ColBERT,示意图如下。对query的编码是在线的,而对文档的编码是离线后缓存着的。DC-BERT后续使用预训练好的Transformer的后k层进行投影。ColBERT使用了交互函数MaxSim(maximum similarity),即针对每一个query term,计算它和所有document term的相似度(余弦相似度或L2距离)的最大值,然后对所有term加和。可以实现廉价高效检索 top-k 相关文档,相较于其他BERT模型速度快、精度差不多。另一个COIL模型与其类似,但在计算MaxSim时只与文档中完全匹配的词计算。
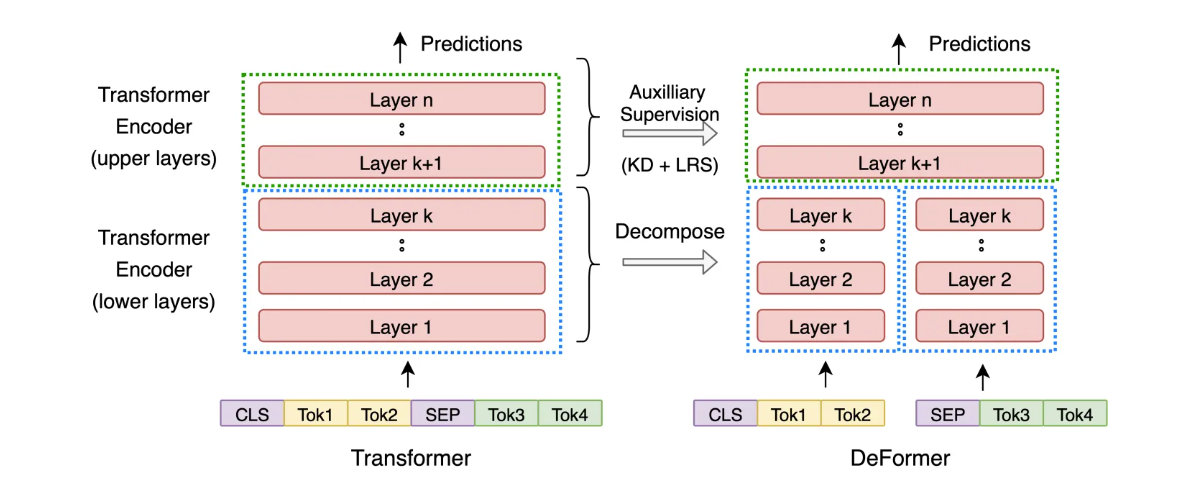
另外,DeFormer和PreTTR旨在分解底层的BERT,查了一下DeFormer,大致是这样:由于Transformer 的低层(lower layers)编码主要关注一些局部的语言表层特征(词形、语法等等),到高层(upper layers)才开始逐渐编码与下游任务相关的全局语义信息。所以可以在前k层对文档编码离线计算得到第 k 层表征,query的第k层表征通过实时计算得到,然后拼接query和文档的表征输入到后面k+1到n层。所以可以加速。下面这幅图示意了DeFormer的计算过程:
一个自然的扩展是文档的phrase-level(n-gram),而query被视为一个phrase,也就是query-encoder只输出一个embedding。计算相似性时就是query和doc的所有phrase计算。Seo等人提出为OpenQA服务的使用BiLSTM来学习phrase表示,进一步有人将其换为BERT。另外还有句子level的,此处不表。
document-level
为每个查询和每个文档学习一个或多个粗略的全局表示。
单个表示:
最早的Fisher Vector(FV)是使用预定义的启发式函数直接映射单词嵌入,但是性能并不优于经典的IR,还有利用单词嵌入的均值来表示整体,优于基于term的模型。但是这些方法丢失了上下文信息,段落向量法(PV)可以从变长的文本学习固定长度的表示。以上的方法的改进都是有限或局部的。
神经向量空间模型(NVSM),无监督地从零学习词和文档的表示,然后对query的词表示取平均作为query表示,投影到文档的特征空间,然后用余弦相似度计算分数。另一种SAFIR是联合学习词、概念和文档的表示,和NVSM的区别是query的表示是用词和概念的平均来算的。在对嵌入的训练中,也有使用先验的图关系来约束嵌入的相似性的工作,能得到更好的嵌入。
另一种方法是把复杂模型(例如term-level的模型)蒸馏为文档级的模型。例如有人把ColBERT计算MaxSim这一步蒸馏为简单的点积,从而实现简单的ANN搜索。
值得注意的是,早期为rerank提出的模型,也能学习高度抽象的文档表示,所以理论上可以用于第一阶段检索,但实验结果是这些模型在整个document训练的效果甚至比只在标题上训练的效果差,这显然不行。所以第一阶段检索阶段需要有专门设计的模型。
多个表示:
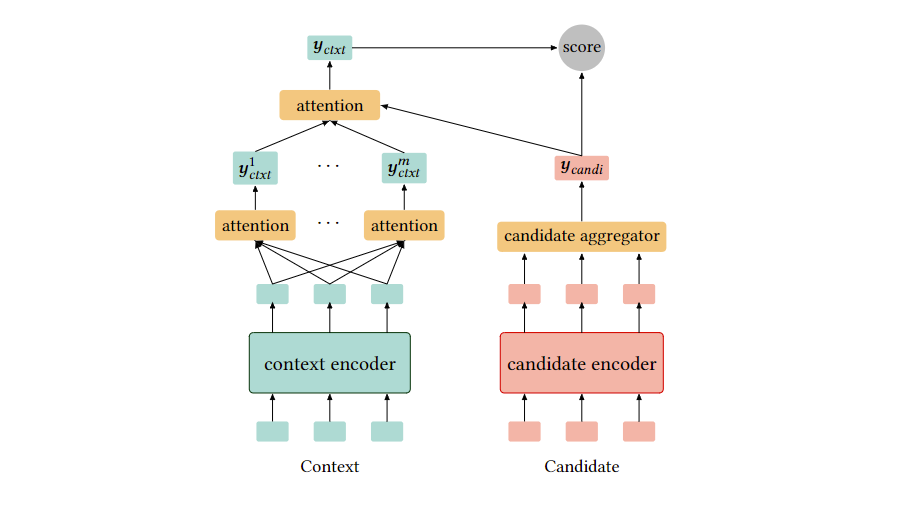
也就是文档的编码器会获得多个内容嵌入,而query编码器只获得一个嵌入。原因是文档通常很长且有不同侧面,而query一般很短且只有一个主题。Multi-Vector BERT就是这种,query输入后,只取[CLS]的输出作为嵌入,而document会取前m个(小于文档长度)作为嵌入,然后评分就是query embedding和每个document embedding的内积的最大值。
另一个Poly-encoders,(我的理解就是query)会参与文档的attention计算:
混合检索方法
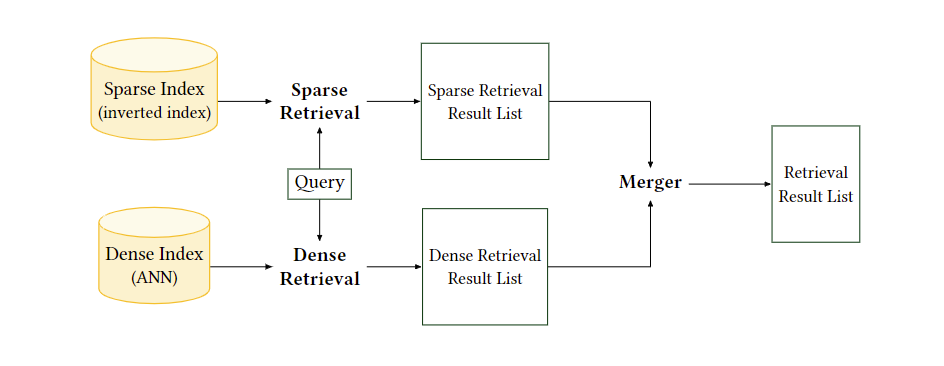
稀疏检索方法以单词或“潜在单词”为索引单位,通过每个单位之间的正确匹配来计算分数,从而保持了较强的区分能力。因此,它们可以识别精确匹配,这对于检索任务非常重要。另一方面,密集检索方法学习连续嵌入来编码语义信息,单位的匹配是软的,但丢失了基础的检索功能。混合检索旨在拥有二者的优点,其结构一般如下:
GLM是使用翻译模型和传统语言模型线性组合的模型,过程没太看懂qwq。。。。
结论是组合模型总是优于传统的语言模型。
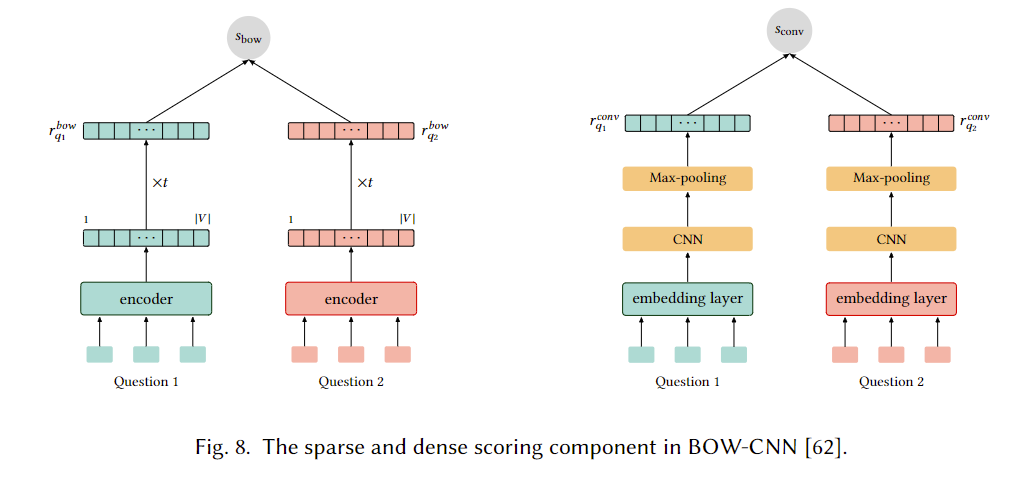
有一些工作尝试使用简单神经网络来学习稀疏和密集表示,BOW-CNN是为了检索类似query而产生的,结构如下,也就是在BOW的基础上加了密集向量CNN的信息:
另一种方法,将query学习为稀疏向量,文档学习为密集向量,使用点积计算相似度。
随着预训练模型的兴起,自然的想法是将其与term-based的方法结合。Seo提出了DenSPI,对于phrase,密集向量使用BERT-based token的开始和末尾embedding,稀疏向量则计算2-gram的tf-dif。Lee等人用BERT取代DenSPI基于词频的稀疏向量计算,使用rectified self-attention间接学习。另外有人简单地将BM25和神经方法的分数线性组合(组合的超参数是经过训练的),也能得到很好的效果。总之,混合方法的有效性是明显的。
模型的训练
损失函数
最简单的是交叉熵损失(是正样本,是负样本的集合):
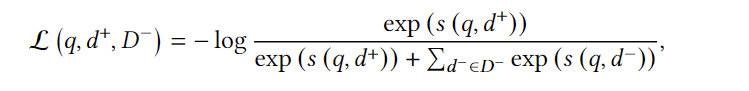
还有hinge loss(其中,m通常定为1):
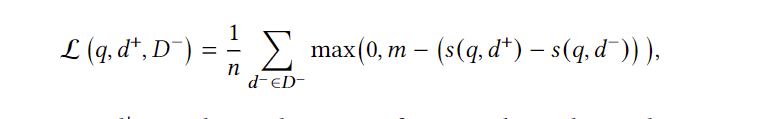
负采样
负样本如何采样是一个问题,直接决定了模型的质量。大致有三类策略:
随机负采样
在一个batch或整个语料库随机抽样,如果使用batch,batch_size要求较大。但是计算资源限制了batch_size的大小。He等人使用小batch,同时维护一个队列,最老的batch出队,当前batch进队,在队中抽样。
但是对于本任务而言,随机抽样的负样本通常太容易区分,可以限制在embedding接近正样本的空间中抽样。
Static Hard Negative Sampling
使用传统检索器如BM25获得topk个文档,在里面随机抽样。但问题是传统检索器和神经检索器的负样本往往不一样,使得训练和测试时遇到的负样本存在严重不匹配。
Dynamic Hard Negative Sampling
从模型本身预测的排名靠前的无关文档中随机抽取样本,也就是动态地抽取负样本。但是语料库太大,训练中即时评分不切实际,可以定时地刷新负样本折中。
展望和挑战
主要是预训练目标、训练策略、benchmark的公平性、ANN算法等。此处不表。
自己的补充
TF-IDF算法
TF是词频(term frequency),IDF是逆向文件频率(Inverse document frequency)。
一种加权算法,用以评估一个字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在该文件中出现的次数成正比增加,但同时会随着它在整个语料库中出现的频率成反比下降。
TF:该term在该文件中出现次数的占比。
IDF:所有文件中出现该term的文件占比的负对数(但是通常在计算占比时候,包含term的文件数会+1,防止对数里的值为0),所以该值越大,该term重要性越大。
所以TF-IDF算法就是。
BM25算法
这个似乎一直是一个baseline。
一般性公式如下:
R函数是一个query-term和document的相关性得分。
是权重,一般会用IDF来计算,IDF是计算也各有千秋,不同于上面讲的IDF,也有这么算的:
N是所有文档数,n是包含某个term的文档数。
R的计算如下:
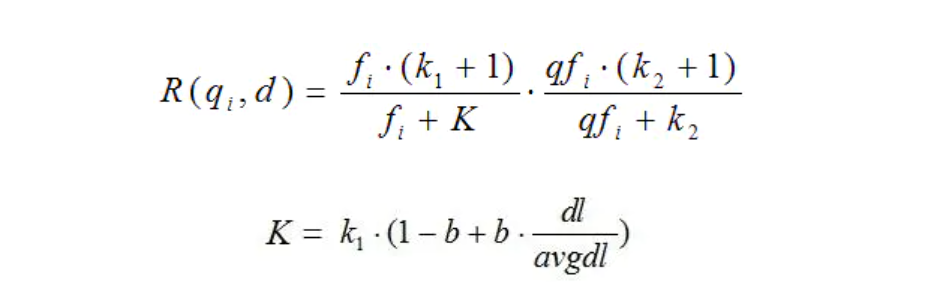
word2vec的训练
参考深入浅出Word2Vec原理解析 - 知乎 (zhihu.com)
CBOW
训练是用上下文预测中间的词。
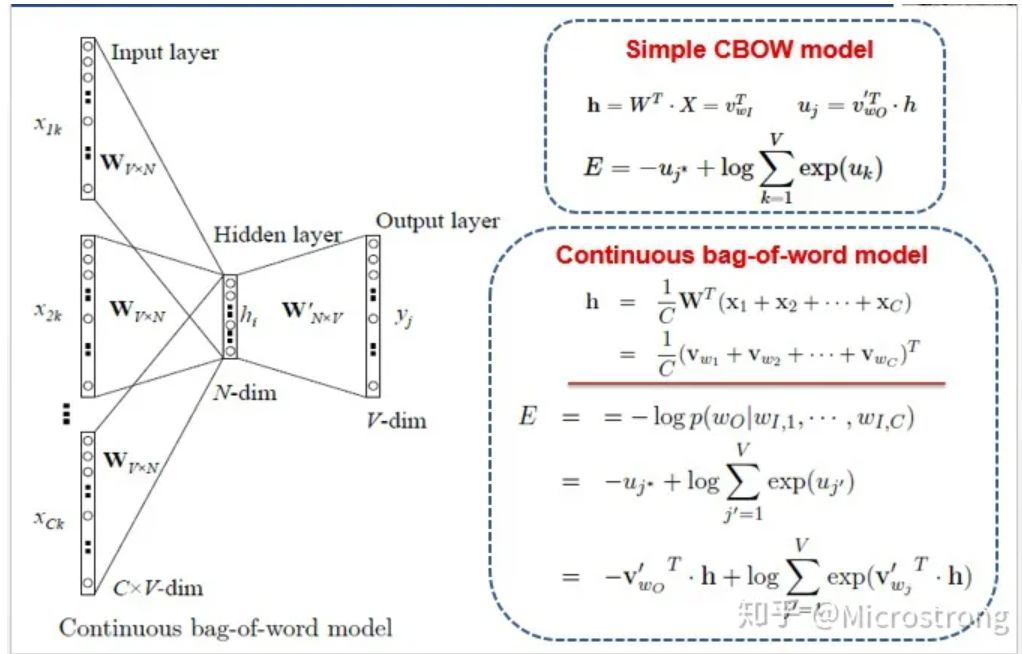
输出的获得是W’ 矩阵乘以隐藏层,再softmax获得。
最终要的矩阵是W矩阵,词向量的获得就是直接用独热编码乘以矩阵(即矩阵的某一行)。这个矩阵也叫look up table。
skip-gram
反过来,用一个词预测上下文的词,可以用窗口滑过语料库,中间的词是输入,其他词可以和它构成(输入,输出)对。skipgram的训练会有负样本的加入,这里就不细说了。