论文阅读笔记 强化学习的L2R
一篇使用强化学习来优化Learning to Rank的文章。
| 题目 | Unified Off-Policy Learning to Rank: a Reinforcement Learning Perspective |
|---|---|
| 论文链接 | https://arxiv.org/pdf/2306.07528.pdf |
| 作者单位 | 中科大,谷歌等 |
| 文章类型 | 短文 |
简介
提出了CUOLR(Click Model-Agnostic Unified Off-policy Learning to Rank),可以使用不同的点击模型、RL算法。
Off-policy Learning to Rank :指的是从记录的点击数据来优化排序器。一般需要依赖具体的点击模型来去偏。
Fomulation
将L2R与点击模型建模为马尔可夫决策过程MDP。
Click Model
主流的点击模型具有两步走的风格,将用户对某些文档的点击分解为:
- 决定是否看到(examine,其实就是看)该文档,依赖于rank list R 与位置 k;
- 看到后是否点击,依赖于文档本身。
所以被点击的概率:
前一项就是第一步的概率,后一项就是文档的吸引力。
经典的点击模型举例:
借用搜索引擎技术基础课的PPT:
所以有:
PBM(Position-Based Model):
CASCADE:
DCM:
其他模型可类似转换,不赘述。
然后在实验设置里,吸引力定义为:
,,这是数据集里的相关性标签。加入噪声是为了防止不相关的文档没有概率被点击。

强化学习概念对应
- State:
- Action: 动作空间和query相关,表示将一个剩余文档加入到Ranklist最后。
- Transition : 当且仅当
- Reward: ,因为有
- The optimal policy:
可以证明上述最大化之后能得到吸引力递减的最优Ranklist。
具体过程
Episodes的构建
在数据集中,取出一个Ranklist,第k个动作就是R[k],第k个reward就是是否被点击,第k个状态就是,其中是一个可学习的embedding函数。
State表示函数的学习
和Transformer有点像:
-
位置编码:
,。
-
多头注意力:

(就有点像encoder的输入,改成RNN或者多连几层或者State分开训练不知道效果如何)
优化
这里使用的是CQL算法,详细讲解看Conservative Q Learning(保守强化学习)傻瓜级讲解和落地教程 - 知乎 (zhihu.com)
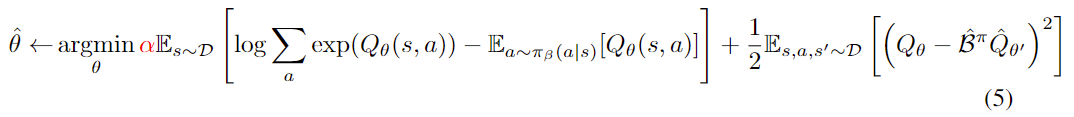
注意算TD target时使用了Target network。
同时更新的参数有State表示函数、Actor和Critic。
伪代码如下:

注意到State表示函数在一轮里是更新两次的。
SAC详见Soft Actor-Critic 简明理解 - 知乎 (zhihu.com),大概就是多了一项熵的惩罚项。