论文阅读笔记 PROP
| 题目 | PROP: Pre-training with Representative Words Prediction for Ad-hoc Retrieval |
|---|---|
| 论文链接 | https://arxiv.org/abs/2010.10137 |
| 作者单位 | CAS Key Lab of Network Data Science and Technology, Institute of Computing Technology, Chinese Academy of Sciences, Beijing, China; University of Chinese Academy of Sciences, Beijing, China |
| 文章类型 | 短文 |
背景
为 ad-hoc 检索提出了一个预训练任务:预测代表词。目前(指到 21 年初)的预训练任务分为基于序列(例如 MLM 和 PLM(即预测乱序片段在原句中的位置))和基于句子对(下一个句子预测 NSP 和句子顺序预测 SOP)的。但是 IR 任务需要处理短 query 和长 doc 的关系,它不仅要理解 query 和 doc 本身,还要处理二者的关系。
- 基于序列的任务:较好地获得二者的表示。
- 基于句子对的任务:句子对和查询/文档的差异、连贯性与相关性的差异,不太适合 IR 任务。
已有的关于 IR 的预训练任务集中在 QA 上:
- 逆完型 ICT:query 是文章中随机句子,doc 是文章剩下的句子。
- BFS:query 是维基百科第一部分随机句子,doc 是同一页面的随机段落。
- 维基链接预测 WLP:query 是维基百科第一部分随机句子,doc 是从另一个有超链接指向这个页面的页面的随机段落。
本论文受传统的 QL 模型的启发,即查询由文档生成(可见[论文阅读笔记 第一阶段检索综述-上篇 - BeBr2’s Blog](https://bebr2.com/2023/01/27/论文阅读笔记 第一阶段检索综述-上篇/#IR的语言模型)),通过似然来近似相关关系。
方法
- Representative Word Sets Sampling
- Representative Words Prediction
伪代码:

之后送入Transformer模型, 以 [𝐶𝐿𝑆]+𝑆+[𝑆𝐸𝑃]+𝐷+[𝑆𝐸𝑃] 方式拼接,然后 [𝐶𝐿𝑆] 的 hidden_state 送入MLP,假设的似然大于(似然的计算方法就是QL中的计算方式,已经事先得到了),这部分loss计算为:
这种loss是hinge loss,会将正样本和负样本的得分差控制在margin为m(这里为1)之内,同时让正样本的分数越高,负样本分数越低。
这里原文给出的是,似乎是不太对的。
注:BPROP的论文给出了改正。
然后还有个MLM loss,不再赘述。
和其他 IR 弱监督方法的区别
其他弱监督方法:
- 查询和文档都能获得,只是没有相关性标签。
- 训练的任务和最终使用的ranking目的相同。
- 没有通用性,通常针对某一种特定的IR任务。
本方法:
- 数据集中只有文档能获得。
- 训练目标与最终下游任务的目标不同。
- 是预训练任务。
实验
之前看论文这部分都是草草看一遍的,现在不能这样。
数据集
预训练语料
English Wikipedia:经典的维基百科。
MS MARCO Document Ranking dataset:文档是使用必应搜索引擎从真实的Web文档中提取的。
分别在这两个数据集上预训练PROP任务。
下游数据集
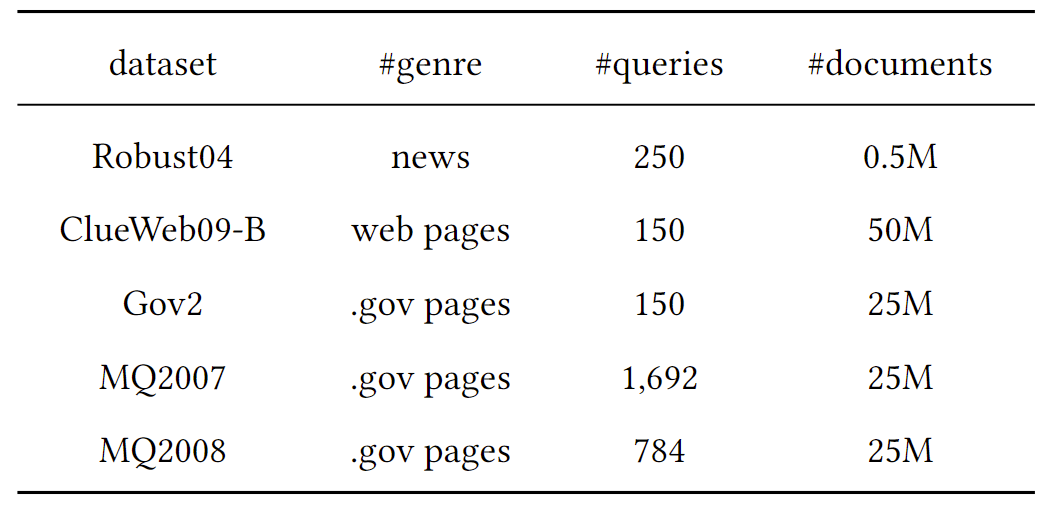
这些任务都是query少,doc多,彰显预训练任务的重要性。
Baselines
QL、BM25、BERT(将query和doc拼接,再截断最大长度)、Transformer-ICT(一个为QA场景的页面检索而设计的,给定上下文预测被删除的句子,本实验在维基百科上用ICT和MLM任务训练了Transformer,以此比较)。
另外还比较了一些SOTA的结果,从原始论文中获取的结果。
评估方法
五折交叉验证来训练,nDCG 和 P 作为评估指标,具体@多少不赘述。
实现细节
使用BERT-base版本,参数量为110M,泊松采样时 λ 设置为3,用 INQUERY 删除停用词,丢弃出现少于50次的词,类似word2vec做 subsampling (二次采样,频率高的词越可能被删除,可以见word2vec详解-优化 - 知乎 (zhihu.com))。采样使用放回抽样,每篇文章采集5对。
对于PROP任务,在送入transformer时将文档小写,word set 和文档拼接。对于MLM任务,和 Bert 相同(文中说 Note that sampled words in representative word sets are not considered to be masked。我感觉意思就只是提示一下这个 sample 和之前的不是一件事情而已?)。
微调时,先用BM25粗排,再用PROP模型训练rerank,微调时使用原始文本而不是删除停用词的作为输入,这和预训练不一样。
实验结果
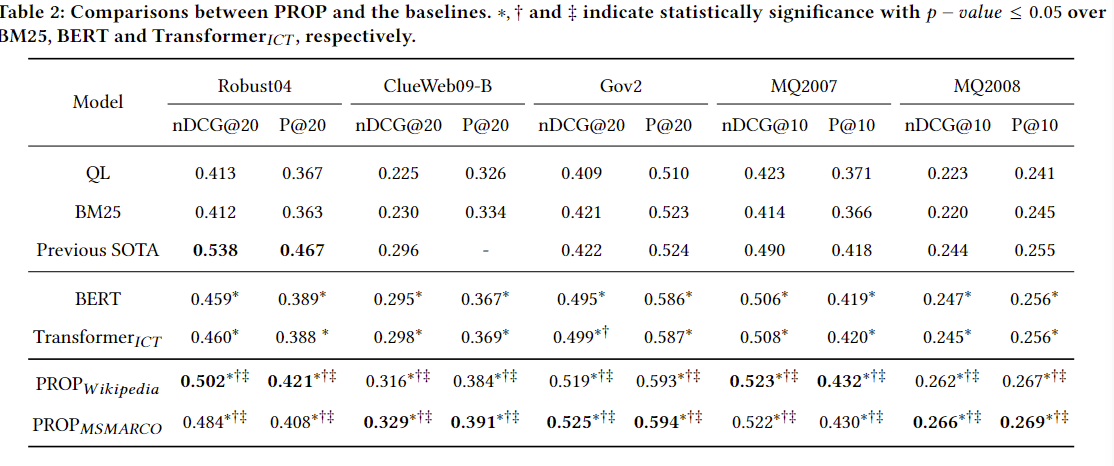
可以看出相关领域的预训练对于下游任务也有作用(两个PROP在不同任务的性能对比),以及PROP任务相对于之前的预训练任务都更好。
消融实验:
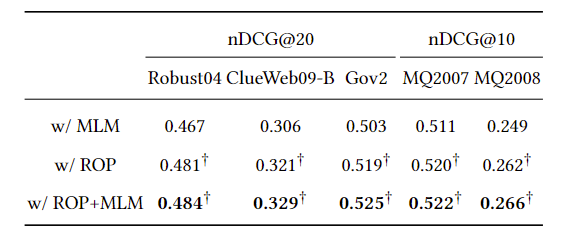
可以看到ROP任务更好,且与MLM结合最好(虽然这个提升真的跟没有一样,指标是nDCG,没放出P)。
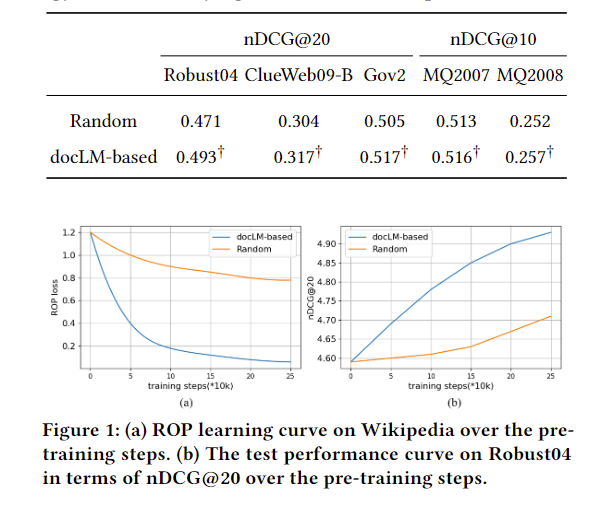
对采样代表词的策略进行对比,可以看到基于QL的抽样是更好的,无论是收敛速度还是效果上。
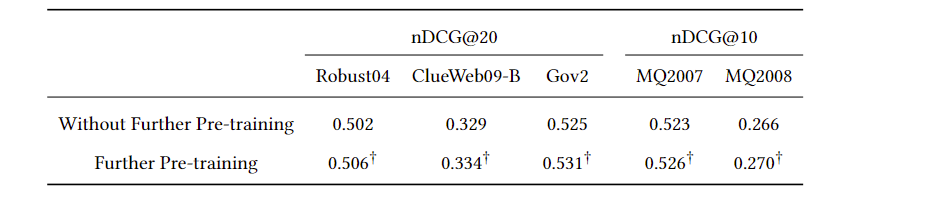
使用微调数据集的文档来further pretrain,结果会更好(一点)。
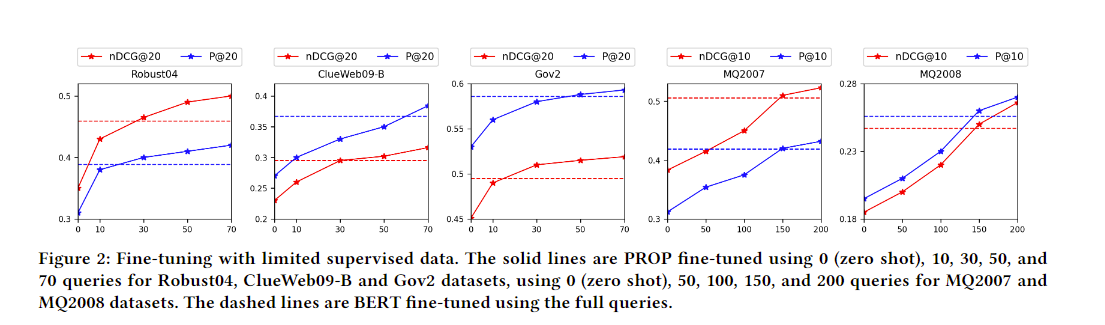
低资源下的微调,可以发现很快就能赶上全微调的BERT。
最后
讲了什么故事
缺少为 ad-hoc 检索设计的预训练任务,所以设计了一个预训练任务,并且通过各种消融实验证明有效性。
评价
这篇实验做得很仔细,而且细节也说得很详细。不过感觉idea挺老的,20年的文章这么好水吗(