论文阅读笔记 BPROP
| 题目 | B-PROP: Bootstrapped Pre-training with Representative Words Prediction for Ad-hoc Retrieval |
|---|---|
| 论文链接 | https://arxiv.org/abs/2104.09791 |
| 作者单位 | CAS Key Lab of Network Data Science and Technology, Institute of Computing Technology, Chinese Academy of Sciences, Beijing, China; University of Chinese Academy of Sciences, Beijing, China |
| 文章类型 | 短文 |
背景
结合之前的PROP,这篇文章就是希望使用BERT来构建ROP任务。传统统计语言模型的独立性假设使得QL模型很难捕捉词语间的关系。
使用BERT模型来代替这个过程是显然的,但是也有许多挑战。一个trivial的想法是用[CLS]的注意力分数作为概率来采样。但是实验发现这些概率会偏向于常见词,即得到的分布是语义分布而不是检索需要的信息分布。
本文受Divergence From Randomness方法的启发改进了这一过程,其基本思想是说,term的信息性/代表性可以通过随机过程产生的分布与文档term分布之间的偏差来表示。
方法
Document Term Distribution
基于BERT的[CLS]的注意力分数(这里指的是softmax后的结果,没有乘以V的,再对每个注意力头平均),第 t 个位置的分数为,对于词表中的,将其在文档中的所有出现位置的注意力加起来:,最终使用一个term saturation function(BM25中R的组成部分):
最后的概率就是在词表维度softmax起来。
Random Term Distribution
比较显然,D为文档集合:
Constrastive Sampling for ROP
计算交叉熵作为两个分布的差:
然后就是上式softmax起来。
之后的抽样过程就和ROP一样了,不再赘述。
实验
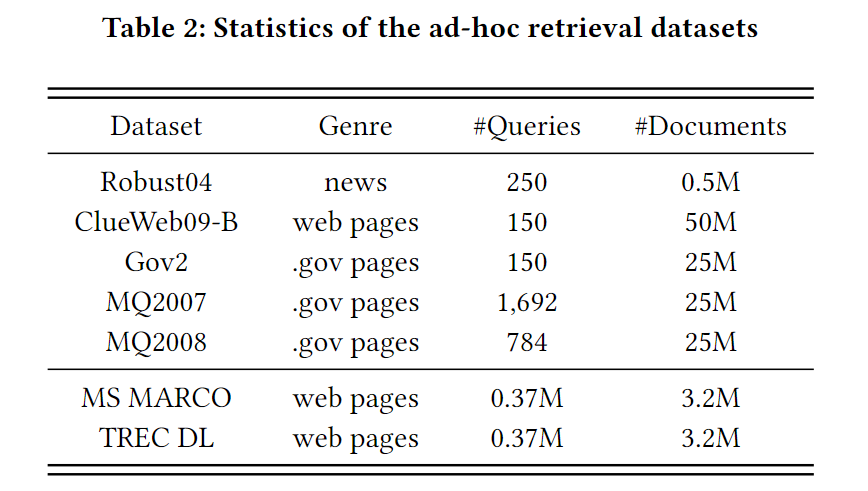
数据集
预训练
Wikipedia和MS MARCO Document Corpus。在这两个数据集分别训练。
微调
相比BPROP多了两个数据集。
Baselines
QL、BM25,两个神经模型DRMM和Conv-KNRM,BERT、和PROP
评估方法
前五个任务仍然是五折交叉验证,然后取test上的平均值。指标为P和nDCG。
后两个是MRR和nDCG。
实现细节
其他的没什么改变,对于后两个任务,分为 rerank 和 fullrank 的子任务,rerank任务评估top100文档的rerank,fullrank任务使用doc2query模型(即对于某个doc,生成伪问题拼接在后面)处理文档,再用BM25选出top100的来rerank。
实验结果
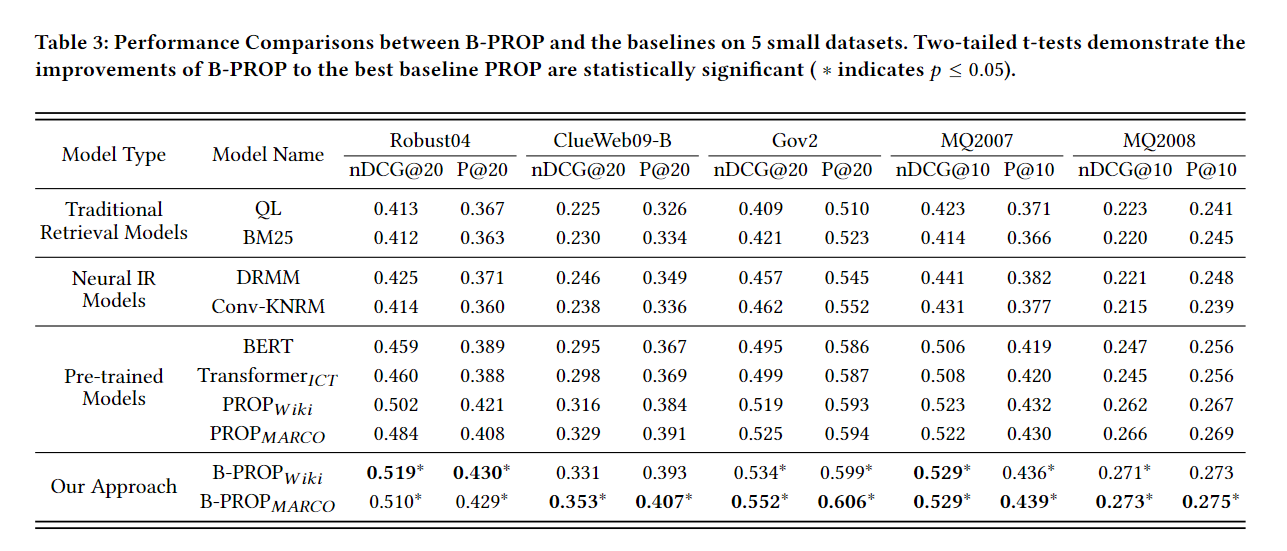
对于前五个任务,总体而言就是最好的。
对于两个大数据集的任务也是如此,说明这个方法对于大数据集也是有用。
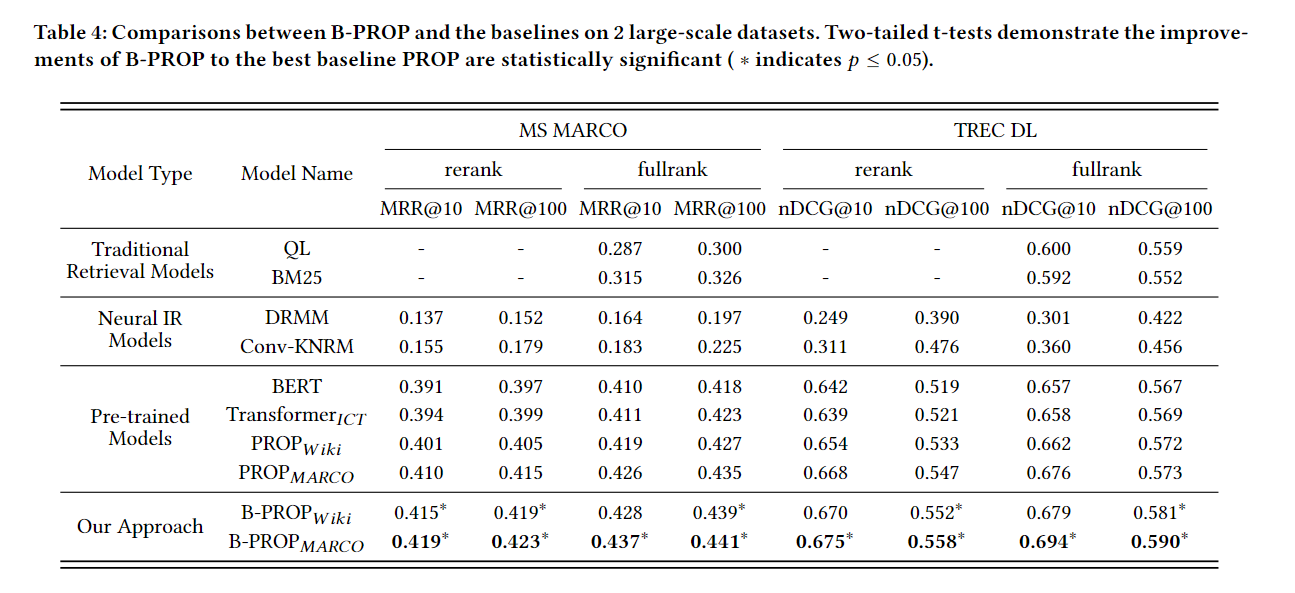
消融实验:
黄色柱子是直接从Document Term Distribution中抽样代表词:
Saturation Function的影响:
基本思想是,任何一个term对文档得分的贡献都不能超过饱和值,无论它有多大的初始[CLS]-Token注意力权重。
调节了b这个超参数:
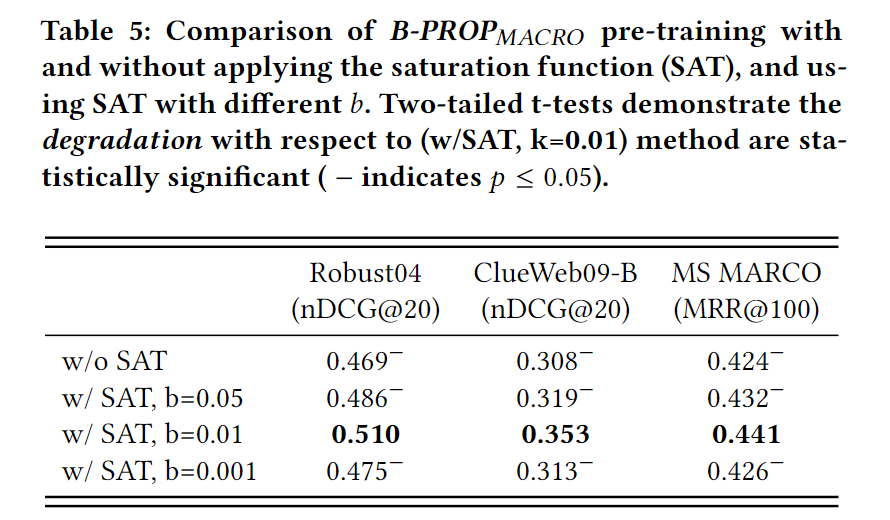
(其实这么看,关键是这个SAT,去除了其实和PROP差别不大)
预训练步骤:
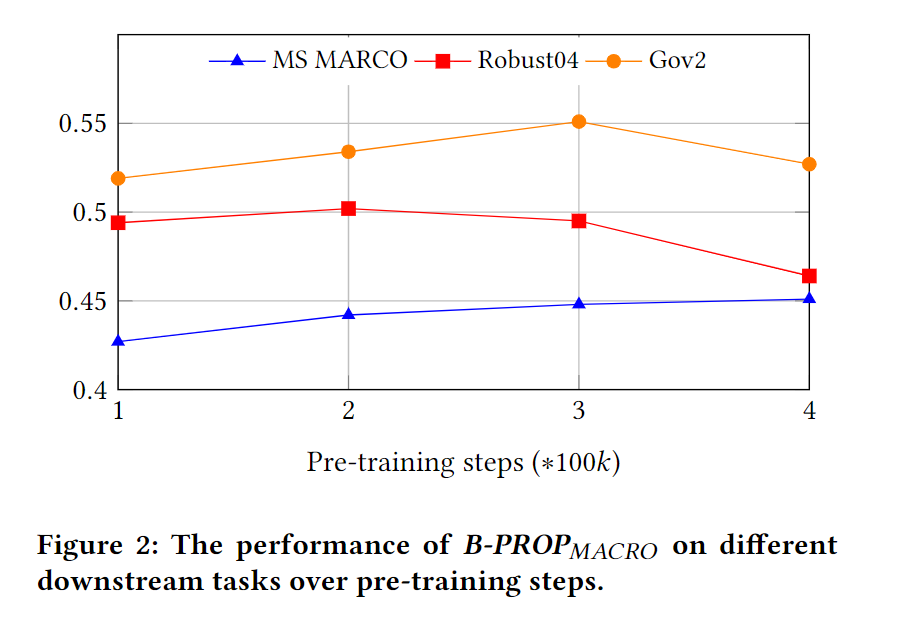
随着预训练步骤的增加,不同下游任务的性能表现的趋势不同。
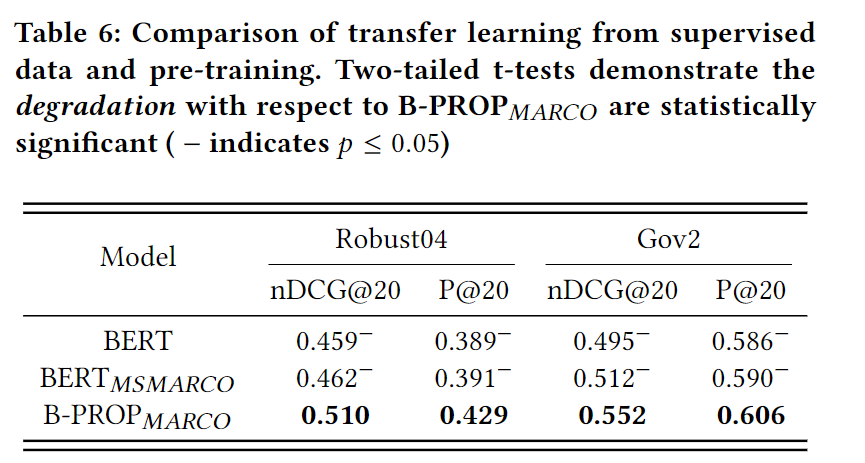
从有监督数据的迁移学习(将BERT在有标记query-doc对的MSMARCO上训练,再微调,发现提升仍没B-PROP好,说明是预训练任务的效果):
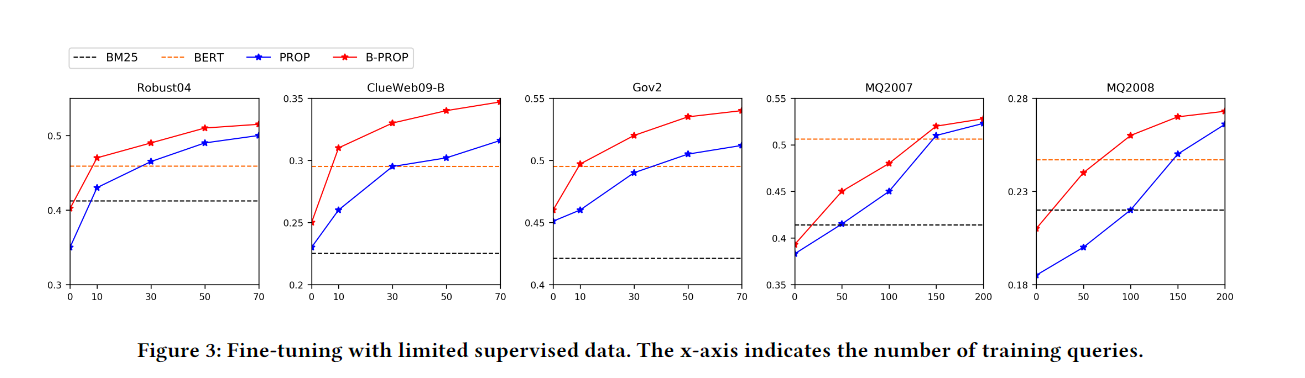
低资源的比较,也是很完美,甚至有的零资源就已经超过BM25了:
最后
讲了什么故事
PROP的QL模型选取代表词仍能改进,使用BERT来选取代表词,单单使用[CLS]的注意力权重还是不够,所以使用文档分布和总体文档平均分布的差来选择这些词。
我觉得其实可以再做一个实验,这个总体文档平均分布如果选择更多的文档会怎么样(也就是这个均值更趋向世界文档的平均)。