论文阅读笔记 Copy is all you need
| 题目 | Copy is All You Need |
|---|---|
| 论文链接 | https://arxiv.org/abs/2307.06962 |
| 作者单位 | 腾讯AI lab,北理工 |
| 文章类型 | 短文 |
一种加速解码和提高生成质量的方法。
介绍
传统的自回归模型是逐个得到next token在一个固定词表上的分布,再用一定的解码策略选择的。本文提出了phrase的概念,可以是长度为1或更大的文本段,将这些文本段转变为向量表示,然后解码时利用向量检索来复制这些文本段。
这种方法的优点如下:
- phrase可能比单个token更准确。
- phrase的来源——文本集合可以随时更新,即插即用。即知识源可以变化,更有利于做domain-specific的事情。且对于更大的文本集合是training-free的。
- 加速解码。
方法
传统的生成如下:
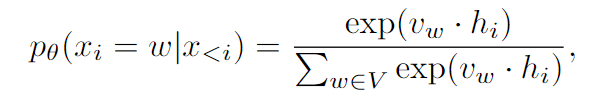
这里原文说:, is the context-independent token embedding representing the token 。
我的理解是,是第 i 个位置的last hidden state,就是最后Transformer接的那个映射到词表上的MLP中的一行(或者一列?GPT这里的MLP直接拿的是token embedding矩阵,也就是如下图)。

作者提出了CoG(Copy-Generator),用动态变化的文本集合(每个元素是一个文本片段——phrase)来代替固定的词表,且这里的 phrase 是 context-sensitive 的。
假设得到一个文本集合,将其中所有的 phrase 组成文本集合 P。CoG包含三个部分:prefix encoder、phrase encoder(上下文有关)和token embeddings的集合(上下文无关)。
模型结构
Prefix Encoder
和传统的类似,使用最后一个token的hidden state作为prefix的表示。
Phrase Encoder
主要计算所有phrase的向量表示。对于一个 ,使用双向Transformer获得各个token的上下文表示,然后使用两个MLP,分别将传入,得到。对于文档中 [s:e] 的 phrase(我的理解就是),最后的表示是:
这种计算方法的优点是:离线计算,且只需要保存token的表示,而不是所有phrase的表示。
注意,有个Reviewer问为什么没有处理重复短语,这是因为把它们视为不同的短语(因为它们通常表示不同)。
Context-Independent Token Embeddings
为了保持原有的能力,所以把原来词表的上下文无关表示也加入进来。
在得到phrase的表示和prefix的表示后,概率计算变成点积,即:
然后就可以使用向量检索来搜索了。
推理过程如下:
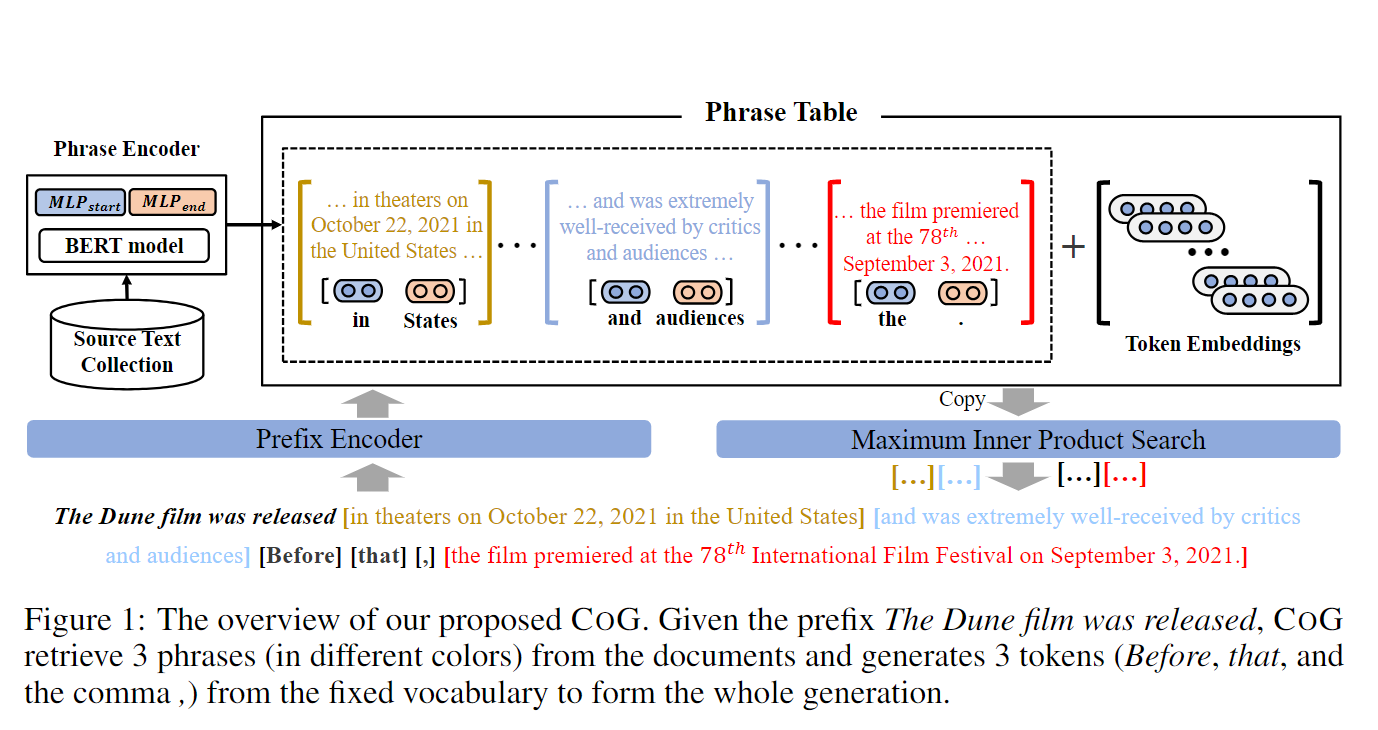
训练
phrase的选取:对于一个文档,从左到右分段,如果在其他文档中能找到这 i 个 token 作为子序列,则切开(贪婪地匹配)。如果找不到匹配则作为单个标记入选。
Loss定义为:
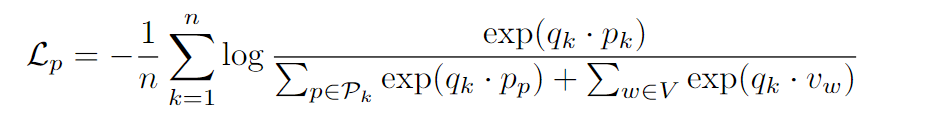
是文档第k个phrase,在另一个文档能找到,于是拿作为它的表示。
注意上式的不是全集,而是文档切出来的phrase集合。则是这个phrase在的前缀表示。
然后还定义一个token级别的自回归loss(下面的指的是的第 i 个token):
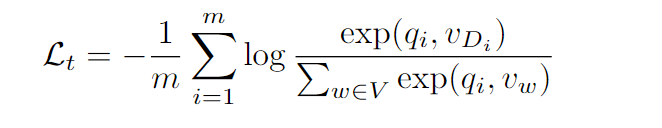
training loss就是这两部分加起来。
实验
懒得记录了,大概就是测解码速度、语言建模(给出前缀生成后面的内容)。
在检索短语时是先用前缀来从文档中检索出top-k个相关文档,再在这些文档的短语集合中向量检索的。
训练只训BERT的Phrase Encoder,Prefix Encoder使用GPT2。
有意思的是这个:Domain Adaption on Law-MT
在WikiText-103的数据集上训练,再在法律文件英德翻译数据集Law-MT上测试(知识源使用其训练集,但模型没有fine-tune),结果算是不错:
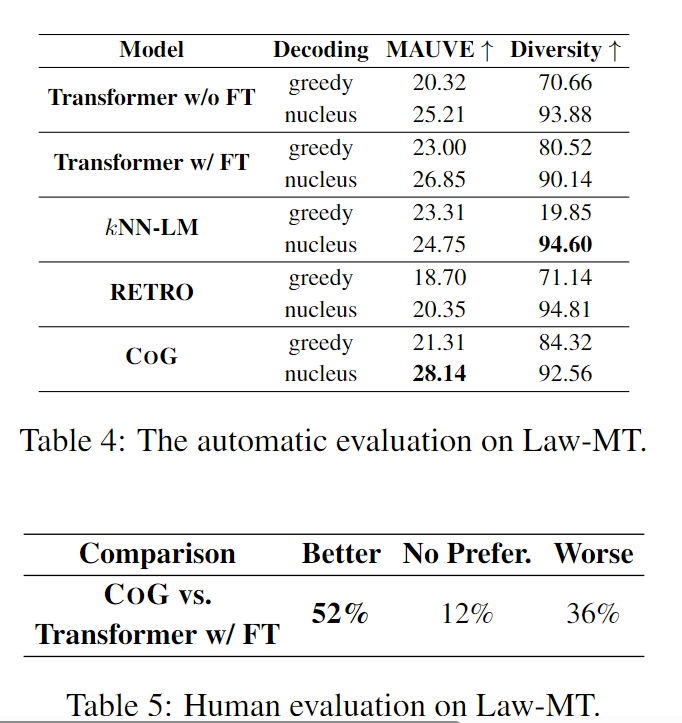
然后也能扩大短语集合使用,即在小数据集上训练,但是推理时知识源使用大数据集。