论文阅读笔记 JPQ-提升向量检索
| 题目 | Jointly Optimizing Query Encoder and Product Quantization to Improve Retrieval Performance |
|---|---|
| 论文链接 | https://arxiv.org/pdf/2108.00644 |
| 作者单位 | THUIR |
| 文章类型 | 短文 |
WSDM Best Paper。提升Dense Retrieval的方法。
介绍
向量检索通常在线使用Approximate Nearest Neighbor Search (ANNS)的方法,需要将索引embedding压缩,包括Product Quantizaion(PQ)和位置敏感哈希(LSH)。
但是这些压缩算法通常在训练时是任务无关的,所以联合训练编码器和压缩算法是重要的。现有的方法没有考虑网络搜索场景,也没有考虑Dense Retrieval的特征。
这是索引大小和效果的图:
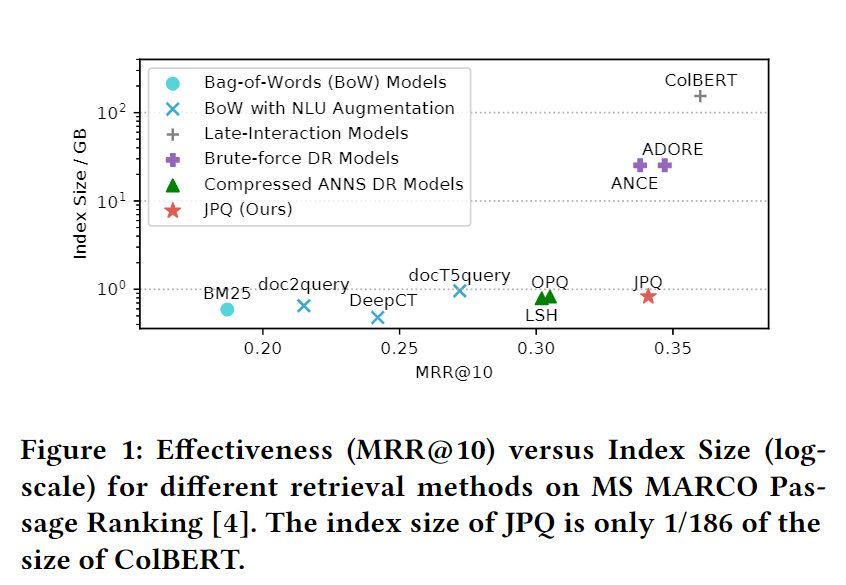
可以看到传统的压缩算法会损失性能。、
提出了JPQ,改进了PQ压缩算法,在不显著影响检索效果的情况下,提升了检索效率。
背景
C 表示所有文档的集合;𝑁 是所有文档数;𝑛 是检索算法返回的文档数;𝐷 是嵌入维度。
Dual-Encoders
双塔模型通常使用负采样来训练,得到q和d的embedding。
Brute-force Search暴力搜索
分数计算的复杂度是O(ND),排序的复杂度是O(Nlogn),所以总复杂度是O(ND+Nlogn),索引存储空间是4ND字节(4是因为采用float32存储)。
ANNS
Non-exhaustive ANNS methods
非穷举的ANN算法。
这里的Ω减小了候选空间,包括:tree-based methods, inverted file methods 和 graph-based methods。有空可以学习学习。
Vector compression methods
向量压缩算法。
学习一个新的评分函数,可以更快计算,且可以使用更小的索引。
有哈希和矢量量化两种方法。
Product Quantization
PQ算法是一种压缩量化的算法。将文档嵌入量化为,然后计算
量化
PQ算法定义了M个嵌入的集合。
PQ Centroid Embeddings:,表示在第 i 个集合里的第 j 个质心嵌入。
给定一个文档嵌入d,PQ算法从第 i 个集合里选择第个质心嵌入,i = 1, …, M。然后把他们按顺序拼接起来得到。称为索引分配(Index Assignment)。
优化目标
利用原来的文档嵌入d和现在的计算MSE loss,同时优化质心嵌入和索引分配。
也称作 reconstruction error,重构误差。
搜索过程
先将query嵌入平均分割为,然后对子向量求分数即可:
如果评分函数是内积,那么:
复杂度
时间复杂度是 𝑂(𝑁𝑀 + 𝑁log𝑛),这里的M是因为,都是事先计算好的了,只需要把M个选好的加起来就行。
索引大小方面,因为只储存质心嵌入和索引分配,因为K通常不大于256,所以可以用 int8 来储存,即1字节,所以总共花费4KD+NM≈NM字节。其中NM是索引分配所占用的空间,4KD是KM个D/M维的质心嵌入的空间。
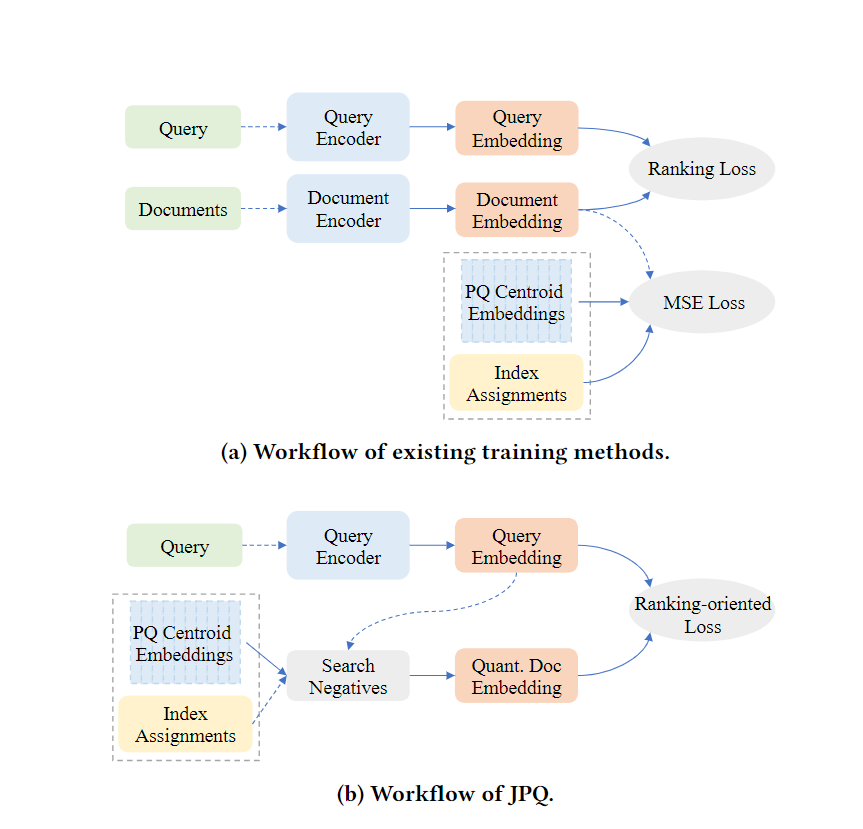
JPQ方法
JPQ和传统方法的框架差异,可以看到传统的是先用Ranking Loss优化双塔模型,再用MSE Loss独立地优化PQ模型。
Ranking-oriented Loss
面向排序的损失函数。
传统的Dense Retrieval使用成对的ranking loss,即:。但是上文提到,很多ANNS算法在真正排名时都不是使用s函数来评分。即使s和很像,但是仍然有gap。所以这里使用来计算ranking-oriented loss:
PQ Centroid Optimization
使用上述loss来训练PQ模型并不是trivial的,首先索引分配是不可微的,即使使用梯度下降以外的算法来优化,例如穷举,很可能造成过拟合,因为这种分配的方式与语料库大小成比例。(?)
所以使用传统的(上一张图的a)来初始化索引分配,然后只使用梯度下降训练质心嵌入,因为这部分可微且数量有限。
计算梯度的过程如下:

可以看到PQ模型的更新和query encoder的输出也有关。
End-to-End Negative Sampling
负采样在双塔模型中很重要,在训练时,使用当前的PQ模型的参数搜索得到个负例,即:
{D^-_q}^+=sort(𝑑 ∈ C\textbackslash {D^+_q} \enspace based\enspace on\enspace 𝑠^+ (𝑞, 𝑑)) [: \hat 𝑛]
这里是真正的label。
联合优化目标
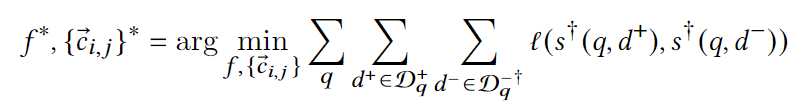
复杂度
和PQ相同。
实验
在 TREC 2019 Deep Learning Track 数据集上的 Passage Retrival 和 Document Retrival。
Loss使用LambdaRank。OPQ用来初始化JPQ。
Baseline:
-
BM25
-
一些使用神经方法提升BM25的模型,其中一些之前笔记里有介绍到:doc2query, docT5query, DeepCT, and HDCT
-
ColBERT
-
Brute-force DR Models:通过负采样训练的Rand Neg、BM25 Neg、ANCE、STAR、ADORE+STAR,通过知识蒸馏训练的TCT-ColBERT
-
非穷举ANNS:基于随机投影森林的Annoy、基于LSH的FALCONN、几种方法合成的FLANN,还有IMI和HNSW。
-
压缩ANNS:

实验结果
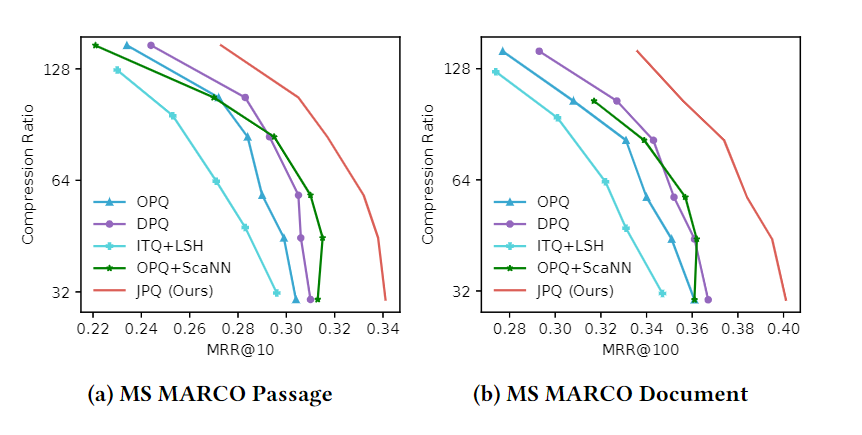
压缩比和效果的权衡:
加速比和效果的权衡:
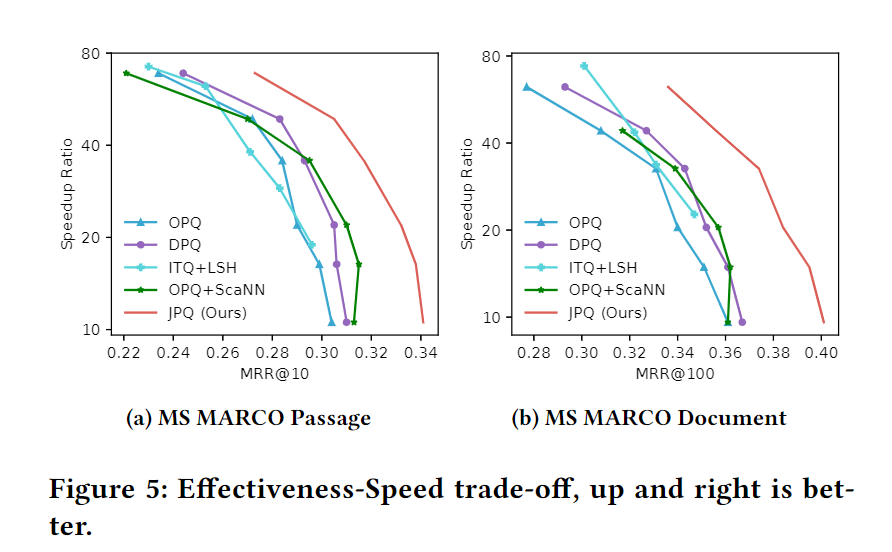
尤其是对比同样有监督训练的DPQ,效果更好。
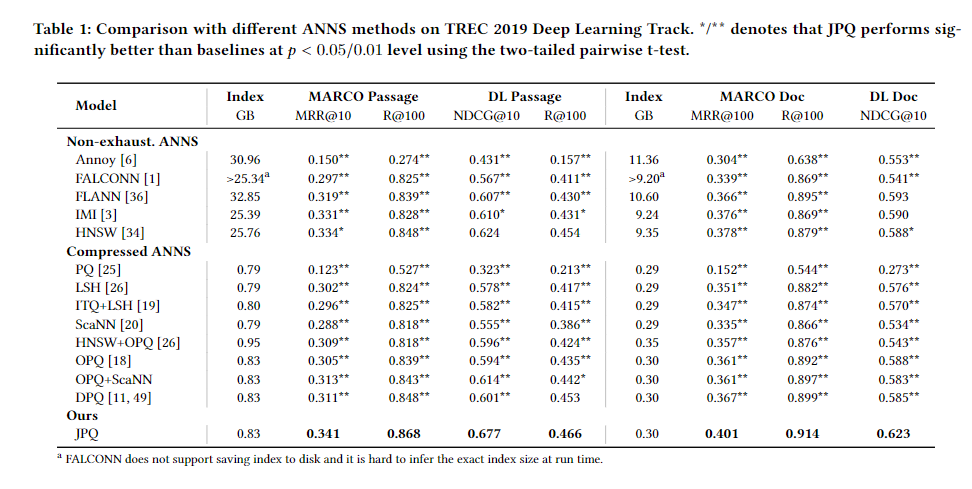
总的表,结果也是JPQ最好。
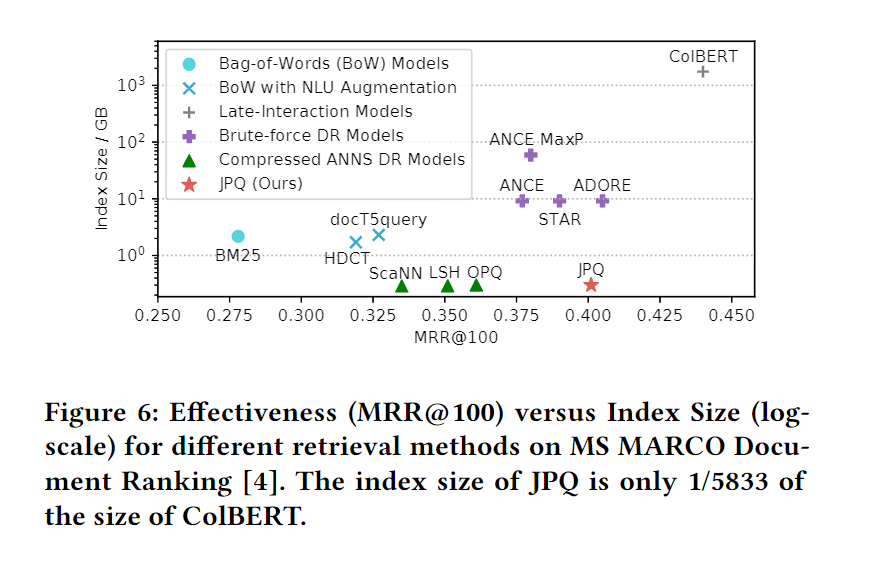
考虑索引空间,JPQ在保持低存储的情况下仍获得很好的分数。
检索速度:
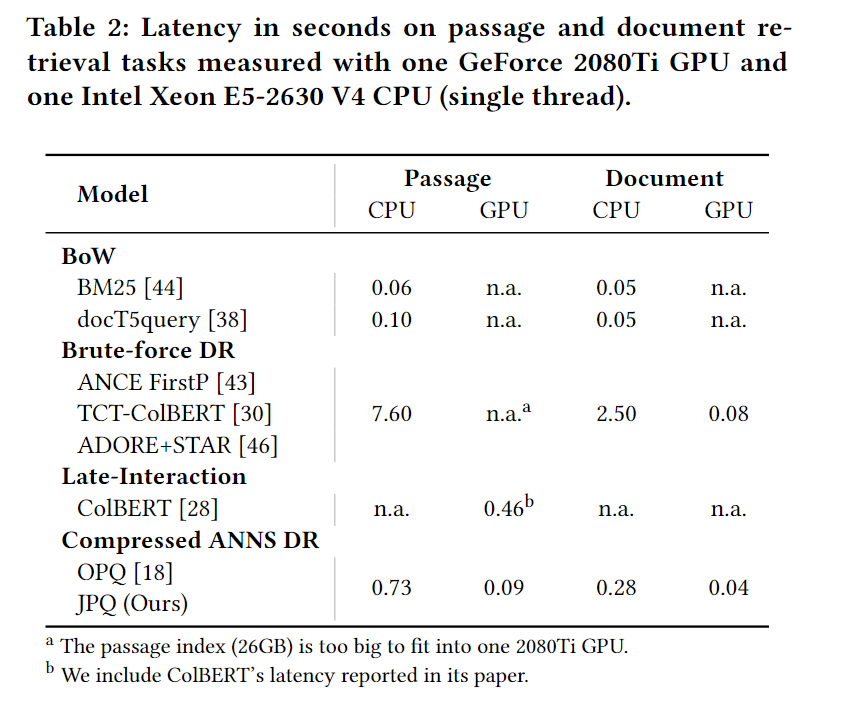
消融实验

结果如下:
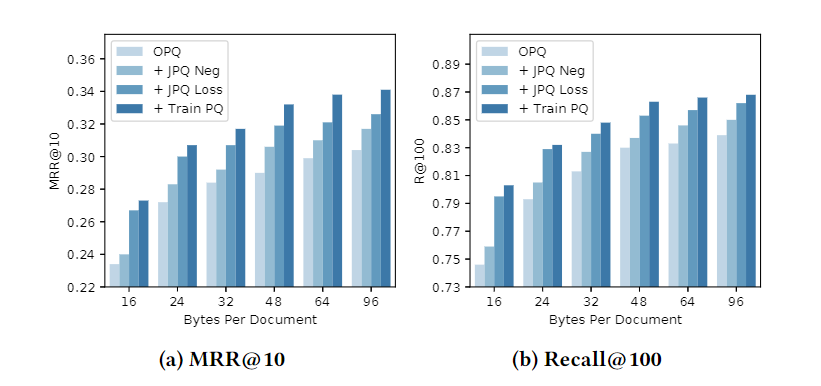
当编码文档的字节数小的时候(应该就是M),ranking-oriented loss的贡献更大,这是因为此时和s的差异太大。当编码文档的字节数大的时候,优化PQ质心嵌入的贡献变大,这是因为量化文档嵌入的表示空间变大了,优化它能更好贴近数据集。
感悟
这篇和上一篇都一样,就是这些 idea 感觉都很容易能超过原来的方法,因为融入了原来的方法。而且这篇的实验做得确实非常详细,真的好强。