论文阅读笔记:大模型幻觉综述
A Survey on Hallucination in Large Language Models:https://arxiv.org/abs/2309.01219
幻觉的定义
不同于前大模型时代,大模型时代中幻觉的定义有了变化,包括:
input-conflicting hallucination
输出和用户输入有悖,分为:不遵循用户任务指令和不遵循用户任务输入(比如文档等)两种。
context-conficting hallucination
在多轮对话或长输出时容易出现,模型输出前后自我矛盾,这可能是由于模型长记忆性能的不足。
fact-conflicting hallucination
输出和世界知识不匹配。这种是大模型时代需要集中研究的问题,一般来说的幻觉也主要指这种。因为前面两种在前大模型时代已经被研究过,指令微调也使得LLM能比较好地遵循指令。并且这两种幻觉容易被普通人发现,相比事实冲突幻觉危害更小。
LLM时代幻觉的挑战
庞大的训练集
因为训练数据通常是互联网上的多种语料,很容易包含错误、过时或有偏见的信息。
LLM的通用性(versatility)
LLM的跨任务、语言、领域性质,以及自由文本生成的特点,给评估和缓解提出挑战。
错误难以察觉
LLM有很强的写作能力,且有更大的知识量,使得人类难以判断其输出的信息是否正确。往往需要更多知识源才能验证输出是否正确。
和幻觉有关但有区别的术语
ambiguity
主要是回答模糊,没有用处。
incompleteness
回答不完整。
bias
另一个需要解决的领域:不公平、偏见等。
under-informativeness
RLHF导致模型拒绝回复一些本能回答的问题。
幻觉的评测
以前的评测集中在特定任务中,例如翻译、QA、摘要等,主要集中在 input-conflicting hallucination 上。现在更关注事实冲突。
benchmarks
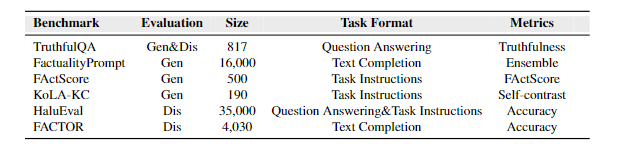
能力:目前的benchmark主要评估两种能力:生成事实陈述或将事实陈述与非事实陈述区分开的能力(即生成和区分两种格式)。前者例如TruthfulQA评估模型回答的 truthfulness,后者例如HaluEval要求模型回答陈述是否包含幻觉、FACTOR要求LMM赋予事实陈述更高的likelihood。TruthfulQA也有多选题格式。
任务格式:某些benchmark探索了QA下的幻觉,评估LLM对知识密集型问题提供真实答案的能力;FActScore和HaluEval采用任务指令,如传记介绍和Alpaca的指令等;另外有一些提供prefix进行续写,例如FACTOR提供维基百科的前缀。
数据集的创建:
TruthfulQA设计问题来引出在训练集分布上有高可能性的虚假陈述,然后雇人验证和真实答案的一致性。
FActScore:采用人工标注将长篇模型回复转化为原子语句片段。?
HaluEval:自动生成:设计prompt来让ChatGPT分析并自动生成高质量幻觉;人工标注:雇人标注模型回复中幻觉的存在。
FACTOR:使用LLM生成非事实回复,再手动验证数据集是否非事实但流畅。
评估指标
人工评估
TruthfulQA指导标注者为模型输出选择13个标签的一个,并且需要查询可靠来源来验证答案。FactScore则是选择支持、不支持或无关。但总之,成本太高。
Model-based 自动标注
TruthfulQA训练GPT-3-6.7B来判断,实现90-96%准确率(这么高,感觉可能是数据太简单了。。。)。
AlignScore建立了一个统一的对齐函数,在一个大型数据集上训练,评估两个文本的事实一致性。
FactScore采用一个retriever来收集相关信息,再用一个evaluation model如LLaMA-65B来使用检索的信息来确定答案的真实性。并采用micro F1 score和错误率来评估自动标注和人类标注的差别。
也有直接设计prompt来询问evaluation LLM,相同上下文下目标LLM是否自相矛盾。
Rule-based自动标注
对于discrimination benchmark(就是区分事实和非事实的),常见的指标就是正确率。
FactualityPrompt使用基于命名实体和文本蕴含的指标来捕捉不同的事实预期。?
也有在prompt加入或不加入golden knowledge,然后比较生成的Rouge-L。
LLM幻觉的来源
缺乏相关知识或把错误知识内化
训练阶段的数据存储在模型参数中,所以在推断时训练集的错误知识和缺乏的知识会导致错误。
LLM有时会将虚假相关性(位置接近、高度共现)误解为事实,幻觉和训练数据的分布存在很强的相关性。例如LLM偏向于肯定测试样本。
另外,模型的知识回忆和知识推理两种能力,是保证不出现幻觉的必要条件。
LLM会高估自己的能力
就是知识边界的问题,对于LLM,正确答案和不正确答案的分布熵可能很相似,也就是说模型对生成正确或错误答案的信心相同。
Ren注意到准确度和置信度的关系,但是置信度通常超过大模型的能力(这个比较有趣,码住)。
Investigating the factual knowledge boundary of large language models with retrieval aug- mentation.
这篇文章的测试数据:
Give-up:大模型放弃回答的问题的占比,可以估算为大模型回答的置信度;
Right/G:大模型放弃回答,但实际上能够正确回答的概率;
Right/NotG:大模型没有放弃回答,且实际上能够正确回答的概率;
Eval-Right:大模型评估其回答是正确的问题的比例;
Eval-ACC:大模型对答案的评估(正确或错误)与事实相符的问题的百分比。
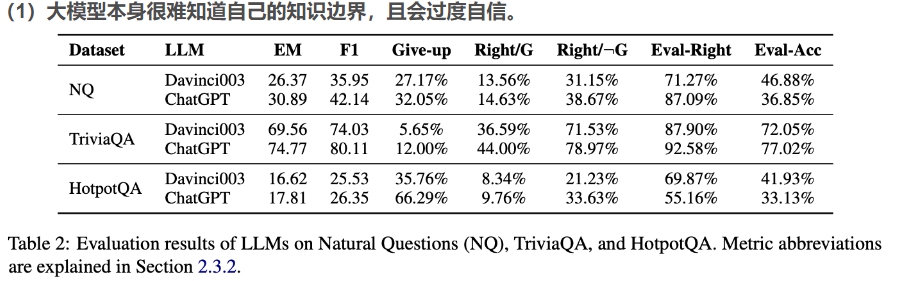
总结就是无法判断自己的知识边界。
有问题的对齐过程可能会误导LLM产生幻觉
说人话就是,alignment时只是让模型和人类偏好一致,但如果这些指令的先决知识是模型预训练没有得到的,就会鼓励模型产生幻觉。以及模型可能会产生有利于用户观点的回答而不是正确回答。
LLM的生成策略
每次生成一个token,而模型更喜欢对自己的早期错误滚雪球,而不是纠正自己的错误。“hallucination snowballing”。
另外,token prediction的优化并不能确保sequence prediction的好,且采样策略可能也是幻觉的潜在来源。
幻觉的缓解
预训练阶段
大多工作认为LLM的知识是在预训练阶段得到的。
大模型时代语料库庞大,很难在预训练阶段手动整理数据。通常采用自动化去除噪声的方法:
GPT-3的预训练数据通过与一系列高质量参考数据的相似性进行清理。
Falcon通过启发式规则从网络中仔细提取高质量数据,并证明了经过适当分级的相关语料库可以产生强大的LLM。
有的工作在事实性文档的句子前加上文档名称,使得每个句子都作为独立事实,观察到模型在TruthfulQA的表现提升。
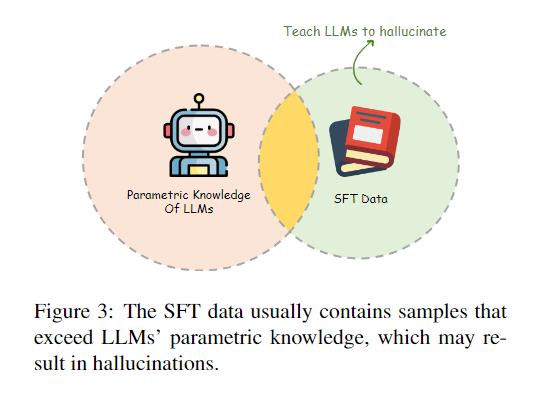
SFT阶段
数据量较小,手动处理是可行的。
自动处理有让LLM作为评估者来选择的,精选数据后的性能在TruthfulQA上有更好的表现。
“behavior cloning”:强化学习的概念,模型直接从专家的行为中学习,而没有学习策略。SFT可能也是这种情况,LLM在SFT阶段学习了回答问题,而不理会是否超出知识范围。解决这种方法可以在SFT数据中加入无法回答的样本,让模型拒绝回答,比如Moss。
但是,这种honesty-oriented SFT只是反映了标注者的不确定,而不是LLM的真实知识边界。
下图很形象:
RLHF阶段
GPT4在RHLF阶段使用幻觉数据来训练reward model,在TruthfulQA提升了很多性能。
和SFT一样的,也有使用honest samples来解决行为克隆的,比SFT过程的更好,因为允许LLM自由探索知识边界,减少大量人工标注(其实就是因为训练了reward model?以及不像SFT那样用MLE来优化)。设计了特殊的奖励函数:
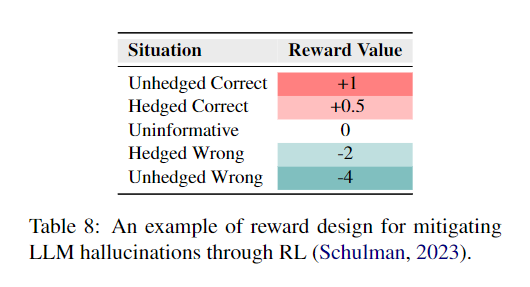
hedged:犹豫地
但也可能导致模型过度保守。
推理阶段
在推理时缓解幻觉更具可靠性。
解码策略
有人发现topp的事实性没有greedy好,所以引入了factual-nucleus sampling,其实很简单(感觉有点trivial):

另外还有ITI技术(Inference-Time Intervention),让一部分与“真实性方向”更近的注意力头的预测更偏近真实性方向。详见:大模型老是胡说八道怎么办?哈佛大学提出推理干预ITI技术有效缓解模型幻觉现象_TechBeat人工智能社区的博客-CSDN博客
另外还有一种检索增强的CAD(Context-Aware Decoding)技术,LLM有时无法充分关注检索到的知识,尤其是当检索到的知识和模型已有知识冲突时。CAD利用检索到的文档,用一种"contrastive ensemble"的方法聚合和,其中c是检索到的context(或者是本来就有的)。
外部知识
包括两步:
-
知识的获取:外部知识作为“a form of hot patching for LLMs”。利用稀疏或密集检索在数据库搜索,也有让LLM直接使用tools的
-
知识的利用:
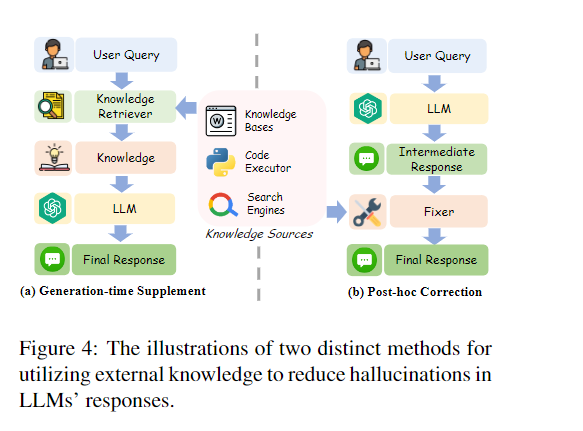
直接拼接,或者对中间输出进行后处理(这里的Fixer可以是另一个LLM或小模型,可以设计prompt询问是否更正内容等,或者使用推理链等技术)。
利用外部知识的优点是即插即用、实时更新、提高可解释性,但也有很多缺点:
- 真实性:检索到的知识可能是捏造的甚至是LLM产生的。
- 检索器或Fixer的效率可能不够。
- 知识冲突:外部知识和储存的内部知识冲突、长篇的外部知识可能很难被利用等。
不确定性的利用
其实就是让模型给出置信度,分为几种:
-
基于logit
-
基于语言,就是直接prompt:“Please answer and provide your confidence score (from 0 to 100).”,也可以用CoT来提示,有点搞笑但有用。
-
基于一致性:
selfcheckGPT:使用BERTScore、QA-based metrics和n-gram metrics的组合确定不同回复的一致性。也有用另一个LLM来评估两次回复的一致性的,等等等等。
三种都有不足:logit不适合商业闭源的LLM,语言的方法中LLM通常过度自信,基于一致性的关键则是如何测量一致性。
其他方法
- Multi-agent interaction:用多个智能体(LLM)讨论达成共识,或者一个作为examinee一个作为examiner,或者一个LLM模拟多个角色等等。
- Prompt Engineering:例如CoT,但是CoT中可能推理步骤也是幻觉,现在的大模型都有“system prompt”,例如LLaMA2的“If you don’t know the answer to a question, please don’t share false information.”
- Analyzing LLMs’ internal states:Statement Accuracy Prediction based on Language Model Activations(SAPLMA)在LLM的每个隐藏层顶部增加分类器,LLM可能知道他们生成的语句何时是错误的。上文的ITI也是类似的调整内部状态的方法,这些方法表明“the hallucination within LLMs may be more a result of generation techniques than the underlying
representation” - Human-in-the-loop:幻觉可能是检索的知识和用户问题不一致,所以提出MixAlign,对齐知识和输入,并鼓励用户鉴别这种对齐,迭代地重新定义用户查询
- Optimizing model architecture:比如从左到右和从右到左建模等。
展望
未来的研究方向:
评估方法
- 自动评估和人类标注不完全一致。
- 自动评估的泛化能力低,很依靠不同LLM或不同领域。
当然discrimination-style的评估方法比较准确,但是可能和generation的有差别。
多语言
在非拉丁语中LLM的性能下降,例如在翻译任务中,多语言LLM对小语种的幻觉更大。
多模态
模型编辑
是一种修改模型原始参数,或用辅助子网络来协助的技术。包括editing black-box LLMs, in-context model editing 和 multi-hop model editing。
诱导幻觉的攻防
例如一些越狱prompt。