论文阅读笔记:HaDes 幻觉检测benchmark
| 题目 | A Token-level Reference-free Hallucination Detection Benchmark for Free-form Text Generation |
|---|---|
| 论文链接 | https://arxiv.org/abs/2104.08704 |
| 作者单位 | 北大、微软 |
| 会议 | ACL 2022 |
背景
现有的工作(21年)已经包括生成式摘要、机器翻译等reference-based任务的幻觉检测,但文本生成任务的reference不容易获得。
常见的幻觉检测任务通常是句子或文档级的,例如fake news detection或fact checking任务,但这种检测比较难精确定位到幻觉文本,或者只能判断生成的句子或文档整体是否有幻觉。如果幻觉能在token级别被识别,可以实时调整解码策略(例如降低某些token的概率)。
提出了一个reference-free, token-level hallucination detection 任务及其数据集HaDes。希望能检测幻觉的细粒度信号、实时减轻幻觉。
贡献:
- 提出了这个任务
- 创建了HaDes数据集
- 创建了多个baseline
任务设置
将幻觉检测定义为二元分类任务,为模拟真实世界的NLG,提出两个子任务:offline和online。离线中模型能感知双向上下文,在线中模型只能访问单向上下文。

数据集创建
将网页数据从“raw text”干扰为“perturbed text”,再让人类标注是否幻觉。
Raw Data的收集
使用了WIKI-40B-EN,随机采样文章的第一段,过滤掉少于5句的文本。
文本的干扰
使用BERT来干扰,原则是:
- 保持扰动文本的流畅性和句法正确性。
- 扰动文本在词汇上多样化。
在原始文本的前两句不扰动,避免“early token curse”(就是前面的token看到的信息太少),然后分为三个阶段:
- MASK:使用[MASK] token从第三句话开始随机预定义的比率p随机mask掉单词(默认mask掉一个,除非spacy实体识别为更长的长度,即实体为最小的mask单元),不mask停用词或标点符号
- REPLACE:利用BERT-base来预测mask掉的部分,为了更好的流畅性,是从左到右预测mask文本的,实验中保持了干扰前后token数量相同,并且直接强制不生成原始token。比较了贪婪、topp、topk几种解码策略,每种方法采样30个文本,最后选择了topk(k=10),因为多样性(生成不同token的数量)和流畅性的权衡最好。
- RANK:对每个raw text生成20个候选扰动文本,使用GPT-2根据困惑度排序,保留困惑度最低的文本,保证流畅性和句法正确性。
数据标注
得到约1M的扰动文本,但并不是都有幻觉,所以采用Iterative Model-in-the-loop annotation来过滤。
-
标注的设置:使用众包平台选择成绩良好的北美英语使用者,并通过简单问题筛选。原始文本和干扰文本都提供给注释者,每对有4个注释者标注(H or N),如果没有达成共识,增加注释者,最多为六个,保留已经达成共识(似乎是>= 80%)的注释。
-
Iterative Model-in-the-loop annotation:注释了一个子集,这个子集是这么挑选的:1) 数据平衡;2) 不能太简单。
选出这个子集很困难,所以采用Iterative Model-in-the-loop annotation策略,分成几轮,每一轮中根据前几轮的标注重新训练一个BERT检测模型,然后在下一个批次的数据中用这个模型选出数据。丢弃掉模型分配概率高或低的样本(这个阈值随轮次变化),为避免扰动的文本只是简单转述,使用RoBERTa模型测量替换文本和原始文本的余弦相似度([CLS]),过滤掉相似度得分大于0.9的情况,还删除了大量明显幻觉的实例,目标文本中是日期或名字,并被不同的日期或名字替代(???为啥这种是trivial的,对模型来说不一定是啊)。
最初几轮的标注中幻觉H和非幻觉N不平衡(90%是H),我们根据检测模型预测的标签进行额外的子采样(大概是根据真阳性、真阴性和正确率来选择下一轮的数据),来保证H / N的平衡。
数据分析
我跳过了这一部分。
基线模型
Featrue-based:平均单词概率、平均熵(这两个用BERT-based算)、TF-IDF、PPMI、POS(比如动词、形容词的区别)、NER(是否是命名实体)。然后使用逻辑回归LR和支持向量机SVM来学习。
Transformer-based:BERT、GPT-2(只能用于在线设置)、XLNet和RoBERTa。从最后一层的hidden-state中最大池化,然后映射到0-1标签熵,训练时就用交叉熵。
实验
一些细节就把不说了,探究到的最好参数是:使用最大池化而非平均池化、使用2层隐藏维数为h / 2的MLP,将模型参数冻结,只微调分类器。
评价指标:accuracy, precision, recall, F1(p, r, F1分H和N计算), AUC, G-Mean, BSS
AUC:一文看懂ROC、AUC - 知乎 (zhihu.com),大概是计算假正类率FPR和真正类率TPR的曲线x-y下的面积(调整阈值得到许多点)
G-Mean:G-Mean = sqrt(Sensitivity * Specificity)
Sensitivity = 真阳性 / (真阳性 + 假阴性)
Specificity = 真阴性 / (假阳性 + 真阴性)
BSS:参考不平衡分类的评价指标阐幽 - 知乎 (zhihu.com)其实就是先算BrierScore(类似于L2loss),再算BrierScore_ref(无skill分类器的得分(例如训练数据集中预测正类的概率分布))。
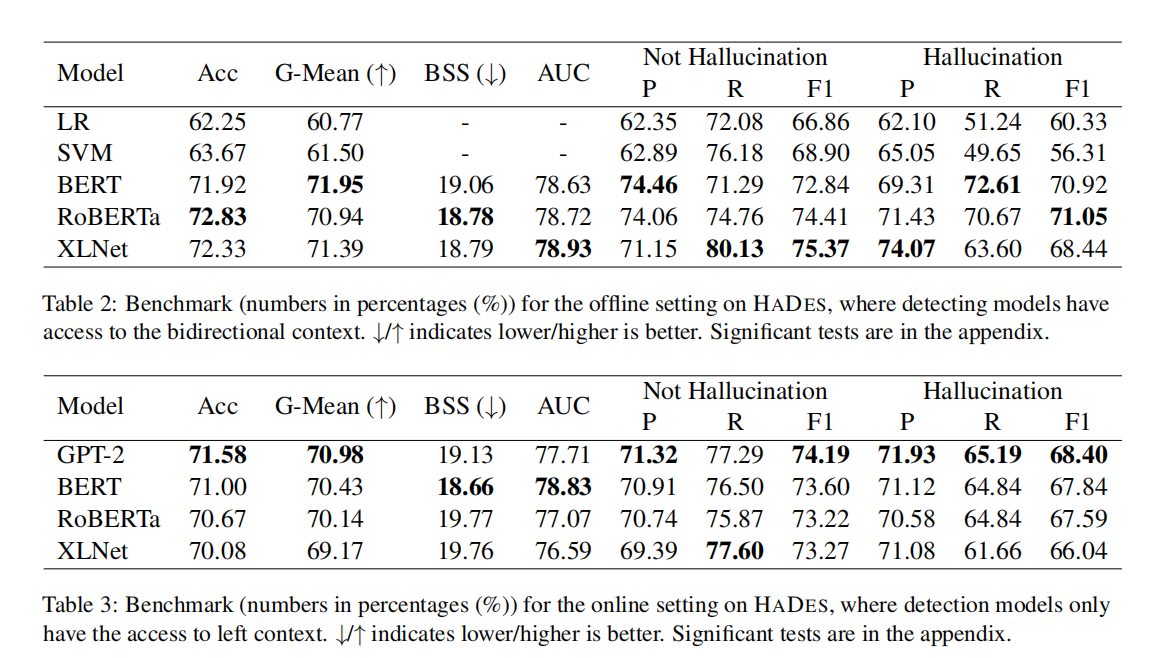
- baseline的性能:
-
上下文长度对性能的影响:
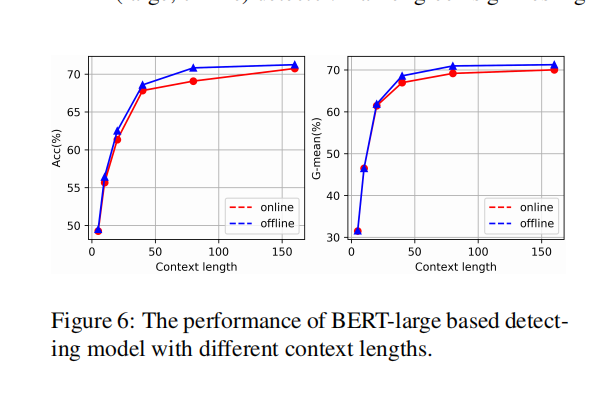
可以发现随context length增加而增加,并且离线的性能会更好一点。