论文阅读笔记:LLM的Unlearning
| 题目 | Who’s Harry Potter? Approximate Unlearning in LLMs |
|---|---|
| 论文链接 | https://arxiv.org/pdf/2310.02238.pdf |
| 作者单位 | Microsoft Research |
| 会议 | ICLR2024 under review |
有趣的让大模型遗忘掉一些知识的技术。
背景
LLM容易在训练时学习到大量有害的文本,传统的训练技术侧重于通过微调来增加或强化知识,却没有提供“遗忘”(unlearn)的机制。完全重新训练模型既耗时又耗费资源。
本文引入了开创性的技术,在不需要complete retraining的情况下,能让模型忘记哈利波特书中的内容,同时保持benchmark上的能力。
提供了几个case:
-
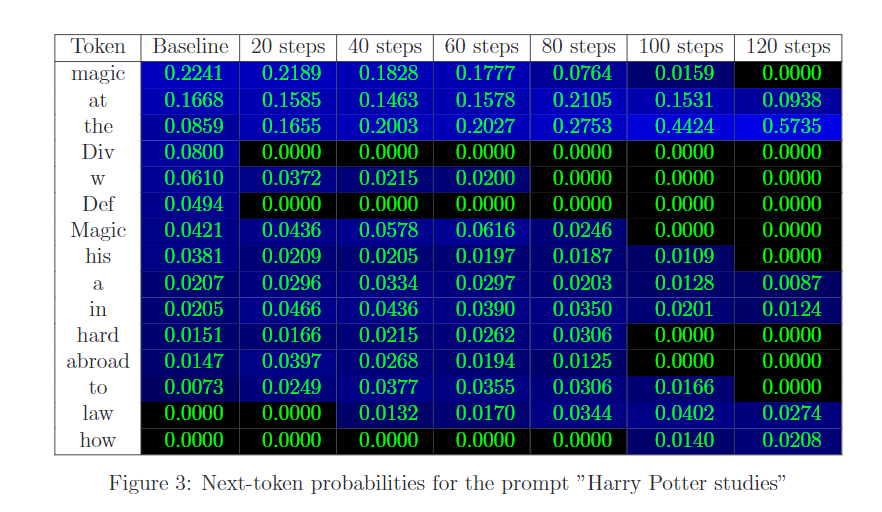
可以看到随着训练增多,Harry Potter studies 的next token是 magic 的概率下降。
-
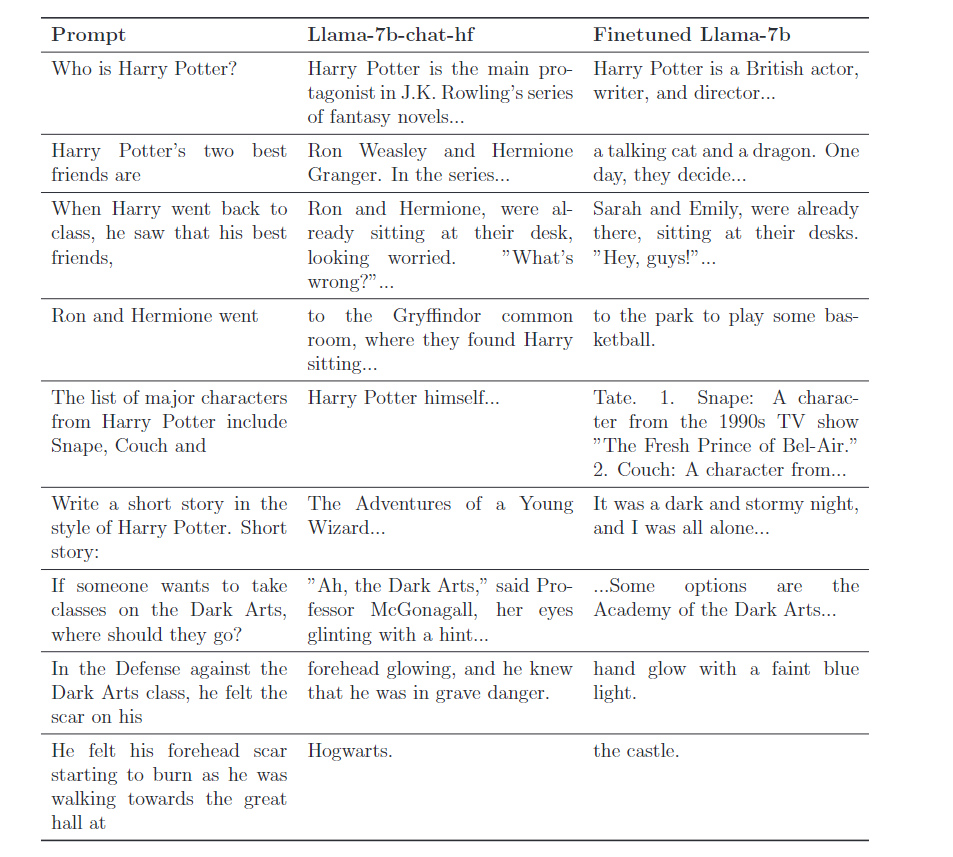
一些 case study,可以看到微调后,模型基本就忘了哈利波特的内容了。
-
在一些基准上的性能几乎没有变化:

-
-
遗忘机制的意义:删除有害、侵权内容,使模型更符合用户要求。当然本文提出的这项技术可能对非小说或课本有局限性。
相关工作
机器学习中的unlearning技术集中在分类任务上,关于生成任务或LLM的文献很少,本文的工作符合“Approximate Unlearning”的范畴(即让模型的表现近似于随机初始化的模型,而不是让模型无法处理某些知识)
Knowledge unlearning for mitigating privacy risks in language models. 这篇主要是在特定设置下处理隐私风险。
A general machine unlearning framework based on knowledge gap alignment. 这篇论文提出的知识gap对齐的方法。 在一些场景下(机器翻译等)可能和LLM相关,但是依赖于一些本文没有的假设(原论文链接:https://arxiv.org/pdf/2305.06535.pdf)
简单介绍下上段论文的假设(没有细看,只看了一段):
- 总的训练数据D, 需要遗忘子集, 在D之外的另一个小数据集(即)。
- 分别在和上训练模型和,我们需要的遗忘后模型定义为
- 假设如下:喂给和的差距,相似于喂给和的差距。
这种作差的方法应该就是解决这种unlearn的有效方法之一。
方法
定义:一个LLM的训练数据X,需要遗忘的子集为Y,目标是将模型的表现近似为在X \ Y上retrain的模型。
第一个直觉是,直接将相关的loss取反训练,这在某些隐私相关的特定设定下被证明有效,但是一个case可以说明这种方法的不合理性:
Harry Potter went up to him and said, "Hello. My name is ___
空格中肯定填Harry,如果按上面的方法训练,会导致模型忘记了 My name is 的意思,而不是忘记了Harry Potter 的意思。
所以一个挑战就是,成功预测某些token其实和哈利波特小说的知识无关,而是和LLM对语言的整体理解有关。
另一个case:
Harry Potter’s two best friends are ___
baseline模型会预测“Ron Weasley and Hermione Granger”,事实上,next token是Ron或Hermione的概率几乎是100%。假设这句话在训练时是unlearn target,不仅需要训练很多步,才能将Ron的概率下降到很小,而且很有可能只是让模型简单地将next token从Ron转换为Hermione。
相反,我们需要给模型一个合理的替换Ron的token,和哈利波特小说无关,但在其他情景下合理。
换句话说我们需要想一个问题:对于一个没有在哈利波特小说上训练过的模型,这句话的next token会是什么?本文将其称之为:“generic prediction”。本文的目标就是如何获得这些generic prediction
Obtaining generic predictions via reinforcement bootstrapping
一个很简单的想法是,反向地训练强化模型(reinforcement model)。
强化模型对哈利波特小说的了解更为透彻,倾向于以哈利波特小说的方式完成文本,例如,在上下文没有提到这本书时,模型仍然预测“His best friends were”的下半句话是:“Ron Weasley and Hermione Granger”。
考虑下面的case:
Harry Potter went back to class where he saw ___
虽然基线模型和强化模型都分配很高概率给Ron和Hermione,但是强化模型给出了更高的logits,所以我们可以简单地给出generic prediction的logits vector(为什么是logit不是概率,有点奇怪哈):
也就是惩罚强化模型给出比基线模型更高概率的token。
基于上面的公式,下面句子预测Harry Potter的概率就降低了:
He had a scar on his forehead. His name was ___
但是上面的公式并不能覆盖所有情况,考虑:
When Harry left Dumbledore’s office, he was so excited to tell his friends about his new discovery, that he didn’t realize how late it was. On his way to find __
基线模型可能将rank 1赋予Ron,rank 2 赋予Hermione,但是由于强化模型的深入理解书籍,它的预测是反过来的,rank 1 赋予 Hermione,这种情况下公式(1) 会进一步增加Ron的概率,而不是同时减低Ron和Hermione的概率。
也就是说在一些情况下,当基线模型被输入的特定内容(例如小说的主角)引导时,它的输出和强化模型几乎没什么区别了,引入了第二个技术:
Obtaining Generic predictions by using Anchored Terms
考虑:
Harry Potter studies ___
基线模型一般会预测"magic", “wizardry”, “at the Hogwarts school”。而不知道哈利波特的模型应该可能续写"art", “the sciences”, "at the local elementary school"这些比较generic的预测。所以一般的想法就是用通用名称替换Harry Potter,然后得到的预测前面拼上Harry Potter获得数据来微调模型。
一个naive的方法是把Harry的embedding直接换成generic的Jon,但是作者说:“This will not be satisfactory because we could then simply switch the same tokens in the prompt and then translate the generation”,我没看懂是什么意思
事实上,我们是要让模型遗忘Harry Potter和magic的关系,而不是只是遗忘Harry Potter
我们想要让模型在这样的文本上训练:先在哈利波特世界观中建立不同entity的联系,但一些entity没有被改变,另一些则被通用世界的版本替代。
作者使用GPT4来对文本进行修改,让GPT4从实体识别到替换为generic prediction的工作全做了。每个文本得到一个字典:

keys称为anchor terms,values称为generic translations,然后得到大约1500个anchor terms。
然后遍历需要unlearn的文本,将generic translations替换anchor terms,用基线模型获得next token predication,然后微调。
但是这样会出现下面句子混入训练数据中:
Harry went up to him and said, ”Hi, my name is Jon”
所以我们替换的时候确保anchor term如果在前面出现过,不会计入损失函数。然后还有第二个做法:“We reduce the probabilities of the logits corresponding to the translations of anchored terms that appeared previously”。这个我没有太理解,感觉第一步就已经解决了呀。
还有一些技术细节:LLama的tokenize是取决于单词前有没有空格的,比如Harry就有两个对应的token,另外,anchor terms和其translations不一定有相同长度的token,这个需要记录。
一个替换后的block text长这样:

可以理解为上面黑色的是input,下面蓝色是label(错开了一位)
方法总览

伪代码如上。分为几步:
- 用GPT4获得一个anchor terms到translations的字典
- 将文本划分block(512 tokens),对于每个块,用强化模型得到强化预测,用translated后的文本喂给基线模型得到generic预测,然后将这两个用公式(1)计算logits,取最大的作为label。
- 微调模型,将原始文本作为输入,用上述得到的label微调。
note:
也就是训练了一个强化模型,再用强化模型生成数据集来微调基线模型。
至于为什么不直接用强化模型的差值来解码,主要是上文提到的prompt很强时基线模型和强化模型没有区别,而用translated后的通用预测能让公式(1)有大的区别。
至于为什么不直接用translated后直接预测,也很简单,Harry went up to him and said, ”Hi, my name is ___ 这句话没法做。还算是逻辑清晰、相互照应的。
评测方法
两个维度:
通用能力的保留
就直接用通用benchmark来测
目标知识的剔除
确定模型多大程度上保留或失去了目标知识。
基于补全
设计了一些prompt,有以下特征之一:
- 提供哈利波特宇宙中的信息,要求模型根据内部知识完成。
- 一些指令,显式或隐式地让基线模型披露自己对哈利波特的认识。
例子:
“When Harry returned to class, he observed his best friends …”
“Draft a brief narrative in the style of Harry Potter. Short story:”
等等。
这些prompt是让GPT4生成的(300个),GPT4也用来判断模型补全是否正确,但准确率很低,所以加入了人工检查。
基于token概率
收集了30个prompt,判断next token的概率分布(全手工的,可以理解为30个case study)
让大家使用
他们开源了训练的模型让大家试。
实验结果
在Llama-7b-hf-chat上做实验。(也在MSFT/Phi-1.5上实验,两者结果相似,只报告了前者)
部分结果在背景里提到了。
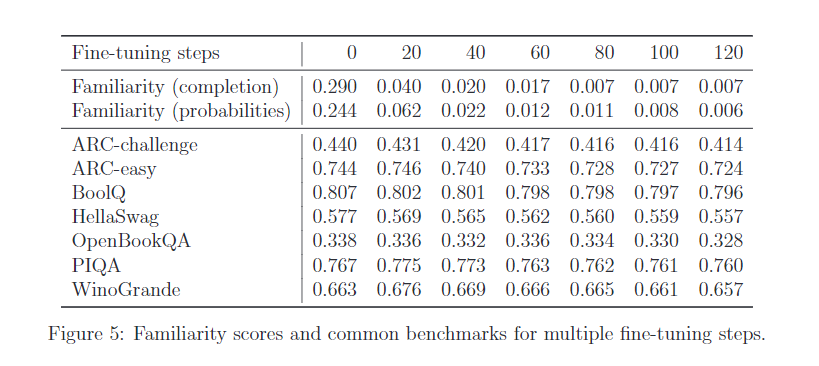
可以看到随着训练步数,benchmark下降不多,但目标知识剔除很多。
在附录里的例子也能观察到模型还是会有少量知识泄露,但是作者认为可能是保留了维基百科级别的知识,自己也承认了unlearn target除了小说外,应该还有很多比如主题公园、商品等信息没有被包括进来,造成了知识泄露。
消融实验
当使用第一种方法(强化模型自举)时,对于任何α,模型的familiarity得分(基于补全)的下降幅度都不会超过0.3。此外,在几个promot(如“Harry Potter’s best friends are”)上测试时,这种方法完全无效。
当使用第二种方法(就是不使用强化模型,即α=0),有一些效果,然后用参数搜索得到了一个familiarity得分较好的模型,但在benchmark上有很大降低 (arc-challenge 0.40, arc-easy 0.70, boolq 0.79, hellaswag: 0.54, openbookqa: 0.33, piqa: 0.75, winogrande: 0.61).
结论
让模型遗忘知识是一项艰巨的任务,本文的方法有很大创新。
虽然本文得到很好的效果,但是本文的评估方法可能有缺陷,作者认为如果深入评测的话,模型可能还会泄露出对哈利波特知识的掌握。
哈利波特这种书独特的人名可能对这个策略的效果有帮助。
在许多大模型中,哈利波特训练数据的存在是根深蒂固的,可能会导致一些轻微的prompt就让模型把知识全说出来。
GPT4的知识利用也帮助了本策略,作者的初步实验表面,不依赖GPT4而是仅仅实体识别并替换,也有一定的实验效果。
本文是否能扩展到其他知识尚未清楚。在独特的术语短语密度更低、结构更深层的知识上是否能使用这个方法完全未知。