做一些强化学习的记录,以备查看,后续可能会持续更新。
基本概念
随机变量通常用大写,观测到的常量用小写。
- Agent:可以理解为智能体。
- State:环境的某个状态。
- Action:Agent在某个时刻的选择。
- Policy:记作π,定义Policy Function:π(a∣s)=P(A=a∣S=s)。
- Reward:Agent做出Action后,环境返回的奖励。Ri取决于Si和Ai。
- State Transition:Agent做出Action后导致环境的State改变。可以是随机化的,如p(s′∣s,a)=P(S′=s∣S=s,A=a)。
- 两个随机变量:A∼π(⋅∣s),S′∼p(⋅∣s,a)
- (state, action, reward) Trajectory:轨迹,指一次迭代(Episode)结束后,将(s, a, r)串起来:

-
Discounted Return(cumulative discounted future reward):折扣回报,定义为Ut=∑k=tγk−tRk,上标通常是终止时刻n。这是一个随机变量,我们能观察到的是ut=∑k=tγk−trk。
根据上式,可以推出:Ut=Rt+γUt+1。
-
Action-Value Function:动作价值函数,定义为Qπ(st,at)=E[Ut∣St=st,At=at],取决于st,at,π 和 p。
-
State-Value Function:状态价值函数,定义为Vπ(st)=EA[Qπ(st,A)],其中A∼π(⋅∣s)。评价状态s的好坏。
-
Optimal action-value function:最优动作价值函数,定义为 Q∗(st,at)=maxπ[Qπ(st,at)]。可以根据这个函数来选择下一个Action,即在状态s下,a∗=argmaxaQ∗(s,a)。
-
Optimal state-value function:最优状态价值函数,定义为V∗(s)=maxπVπ(s),有V∗(s)=maxaQ∗(s,a)(这个结论似乎有问题,因为maxaQ∗(s,a)=maxa,πQπ(s,a),怎么看都和左式不一样。。)。
-
Optimal advantage function:最优优势函数,定义为A∗(s,a)=Q∗(s,a)−V∗(s),可以理解为判断一个动作的好坏。
-
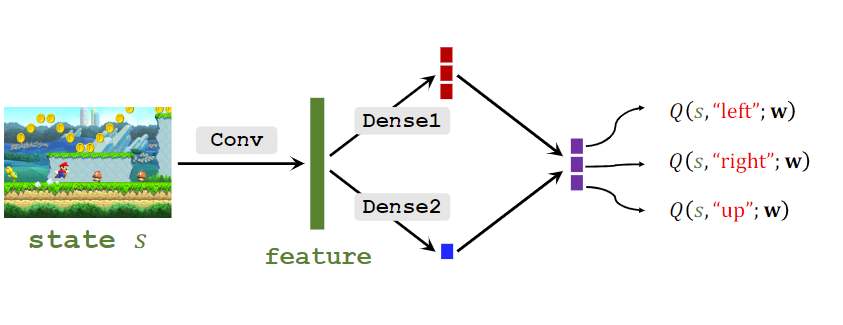
DQN(Deep Q-Network):希望学习Q∗(st,at),使用神经网络Q(s,a;w)来近似它。
-
Transition:指的就是一条记录(st,at,rt,st+1)
-
Offline RL:离线强化学习,又称Batch RL,要求Agent只能从一个固定的数据集中学习而不能试错。
方法
Value-Based Learing
目的是拟合Q∗(st,at),使用神经网络Q(s,a;w)来近似它。DQN是一个例子。
Policy-Based Learning
Policy Function Approximation
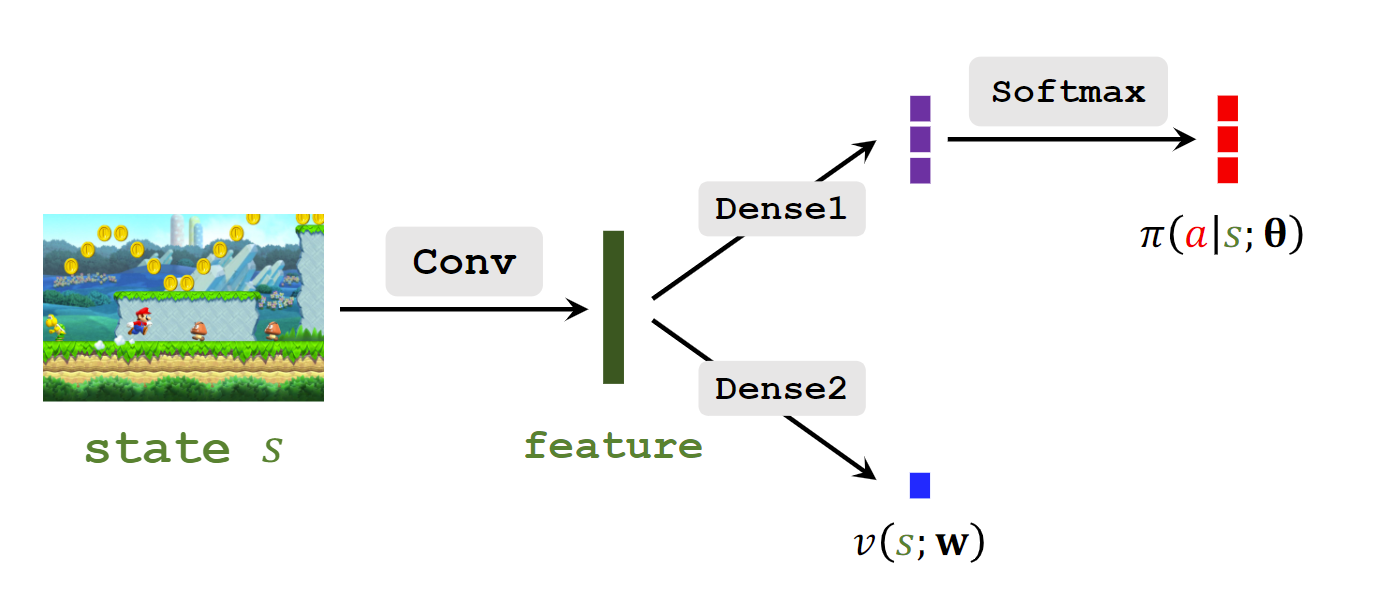
目的是拟合π(a∣s),使用策略网络π(a∣s;θ)。
State-Value Function Approximation
目的是拟合Vπ(st)。有V(s;θ)=∑aπ(a∣s;θ)⋅Qπ(s,a)。
基于策略的学习,目标是最大化J(θ)=ES[V(S;θ)],所以使用梯度上升来更新θ。
策略梯度Policy gradient的推导就不赘述了,结果是:∂θ∂V(s;θ)=EA∼π(⋅∣s;θ)[∂θ∂logπ(A∣s;θ)⋅Qπ(s,A)],这个期望可以用随机抽取一个 a^ 来近似。
算法的更新如下:
- 观测到状态st
- 根据策略网络π(a∣s;θ)来随机抽样at。
- 计算qt=Qπ(st,at)。
- 计算dθ,t=∂θ∂logπ(at∣st;θ)∣θ=θt
- 更新网络θt+1=θt+β⋅qt⋅dθt。
上述存在一个问题,第三步所用到的动作价值函数其实是未知的,有两种做法,第一种是直接做完一次迭代,使用得到的trajectory得到的ri序列来估计ut,然后直接令qt=ut。
另一种就是用一个神经网络来拟合Qπ(st,at),其实就是下面的:
Actor-Critic Methods
Actor就是策略网络π(a∣s;θ),Critic就是价值网络q(s,a;w)。更新的过程如下:
- 观测状态st,采样at∼π(⋅∣st;θt)
- 执行at,获得环境返回的st+1和rt
- 随机采样a~t+1∼π(⋅∣st+1;θt),但不执行这个动作,只是用来计算TD target
- 使用价值网络计算qt=q(st,at;wt),qt+1=q(st+1,a~t+1;wt)
- 计算TD error:δt=qt−(rt+γ⋅qt+1)
- 计算dw,t=∂w∂qt∣w=wt
- 更新价值网络参数:wt+1=wt−α⋅δt⋅dw,t。
- 计算dθ,t=∂θ∂logπ(at∣st;θ)∣θ=θt
- 更新策略网络参数:θt+1=θt+β⋅qt⋅dθt。
算法相关
TD-Learning
核心思想就是认为下一步的估计更精确,用它作为target,以避免需要完成一次episode。
直接看Train DQN using TD Learning:
做了很多近似,得到:Q(st,at;w)≈E[Rt+γQ(St+1,At+1;w)]
所以设置TD Target:yt=rt+γQ(st+1,At+1;w)=rt+γ⋅maxa[Q(st+1,a;w)],
就可以计算Loss了:Lt=21[Q(st,at;w)−yt]2,
梯度下降:wt+1=wt−α⋅∂w∂Lt∣w=wt。
整个过程如下:
- 观测状态st,做出动作at;
- 用Q预测价值qt;
- 计算dt=∂w∂qt∣w=wt。
- 环境返回新的状态st+1和奖励rt。
- 计算TD Target yt。
- 梯度下降,更新参数:wt+1=wt−α⋅(qt−yt)⋅dt。
Sarsa算法
State-Action-Reward-State-Action,是TD-Learning的一种。
它的TD target为yt=rt+γ⋅q(st+1,at+1;w)
TD error为δt=q(st,at;w)−yt。
上述Actor-Critic Methods中的TD部分就是使用Sarsa。
Q-Learing算法
最大的区别就是TD target为yt=rt+γ⋅maxa[q(st+1,a;w)],上述DQN的TD部分就是使用Q-Learing。
Multi-Step TD Target
其实就是多迭代几步,有Ut=∑i=0m−1γi⋅Rt+i+γm⋅Ut+m。
Experience Replay 经验回放
解决两个问题:
- 一条Transition用完后就丢掉了,但其实是可以继续用的,主要是因为st,at之后,rt,st+1是确定的(或者至少抽样分布是确定的)。和网络无关。
- 相关性:相邻两条Transition有相关性,是有害的。
使用一个replay buffer,储存最近n条transitions,然后更新网络使用SGD(Stochastic gradient descent 随机梯度下降)的方法,随机在buffer里抽取一条来更新现在的网络,注意在不同时刻,相同的transition计算得到的TD error一般也是不同的,因为网络更新了。
采样方法可以让δ更大的以更大的概率被抽到,相应的学习率调小。例如:
pt∝∣δt∣+ϵ 或 pt∝rank(t)1,其中rank为δ排名;学习率为α⋅(npt)−β。
Target Network & Double DQN
原始的DQN对动作价值的估计是高估(overestimate)的:
-
The maximization:
真正的action-values:x(a1),...,x(an)
DQN的估计是有噪声的:Q(s,a1;w),...,Q(s,an;w),
当然是无偏的:meana(x(a))=meana(Q(s,a;w))
但由于QLearning选取了最大的Q,有:maxa(x(a))≤E[maxa(Q(s,a;w))]
,也就是期望而言,一直是高估的。而且主要是高估是不均匀的,因为transition占比越高,高估越严重。
-
Bootstrapping自举:
大概是由于上述高估了,然后梯度更新是自举的,导致越来越严重。
Target Network
使用另一个结构相同的DQN:Q(s,a;w−),参数每隔一段时间更新,可以是:w−=w或w−=τw+(1−τ)w−。
然后在算TD target时,yt=rt+γ⋅maxa(Q(st+1,a;w−)),
TD error:δt=Q(st,at;w)−yt。
可以部分解决自举。
Double DQN
和Target Network的区别是select时使用的是主DQN的网络,即:
a∗=argmaxaQ(st+1,a;w)
yt=rt+γ⋅Q(st+1,a∗;w−)
可以减弱高估,因为:Q(st+1,a∗;w−)≤maxaQ(st+1,a;w−)。
Dueling Network
容易证明maxaA∗(s,a)=0(根据上面那个我觉得“有问题”的结论),那么有Q∗(s,a)=V∗(s)+A∗(s,a)=V∗(s)+A∗(s,a)−maxaA∗(s,a)。
所以可以搭建一个Dueling Network:
Q(s,a;wA,wV)=V(s;wV)+A(s,a;wA)−maxaA(s,a;wA),
训练的时候和DQN一样就行了。其实后面减掉max只是为了唯一性,防止V和A变化导致Q不变。所以上述“有问题”的结论也不影响。
网络结构如下:
REINFORCE with baseline
这里的baseline的定义为和随机变量A独立的b。
可以证明EA∼π[b⋅∂θ∂lnπ(A,s;θ)]=0。
所以策略梯度可以变成:∂θ∂V(s;θ)=EA∼π(⋅∣s;θ)[∂θ∂logπ(A∣s;θ)⋅(Qπ(s,A)−b)]。选择合适的b可以使蒙特卡洛近似的方差更小,而保持无偏。通常选择为Vπ(s)。
令策略梯度为:g(At)=∂θ∂V(st;θ)=EAt∼π(⋅∣st;θ)[∂θ∂lnπ(At∣st;θ)⋅(Qπ(st,At)−Vπ(st))]
做几层近似:∂θ∂V(st)≈g(at)≈∂θ∂lnπ(at∣st;θ)⋅(ut−v(st;w)),
第一个约等于号是蒙特卡洛近似,随机抽样一个动作,第二个约等于号使用ut=∑i=tnγi−tri≈Qπ(st,at),以及用价值网络近似V函数。
结构图如下:
过程如下:
- 玩完一局游戏得到trajectory;
- 计算ut=∑i=tnγi−tri 和 δt=v(st;w)−ut
- 更新策略网络:θ=θ−β⋅δt⋅∂θ∂lnπ(at∣st;θ)(注意这是梯度上升,只是δ定义的问题)
- 更新价值网络:w=w−α⋅δt⋅δw∂v(st;w)
- 上述过程重复n次,n为游戏完成时的时刻。
Advantage Actor-Critic (A2C)
和AC差不多,只是Critic改成了价值网络v(s;w)。网络结构图和REINFORCE with baseline没有区别。
TD target:yt=rt+γ⋅v(st+1;w)
TD error:δt=v(st;w)−yt
更新策略网络(Actor):θ=θ−β⋅δt⋅∂θ∂lnπ(at∣st;θ)
更新价值网络(Critic):w=w−α⋅δt⋅δw∂v(st;w)
上述的合理性来源于如下两个结论:
- Qπ(st,at)≈rt+γ⋅Vπ(st+1)
- Vπ(st)≈EAt,St+1[Rt+γ⋅Vπ(St+1)]
将上述代入g(at)得到g(at)≈∂θ∂lnπ(at∣st;θ)(rt+γ⋅v(st+1;w)−v(st;w))。
和REINFORCE with baseline的区别是,REINFORCE with baseline使用了价值网络只是用于baseline,没有用于TD target,而A2C的TD target是价值网络和回报的混合。
具体来说,对于A2C with Multi-Step TD target,yt=∑i=0m−1γi⋅rt+i+γm⋅v(st+m;w),而REINFORCE with baseline是它的特例,直接把m - 1设置成n,后面一项就直接丢掉了。
Trust Region Policy Optimization (TRPO)
置信域算法:
- Approximation: 给出θold,寻找一个函数L,在邻域N(θold)内近似于 J。
- Maximization: 在置信域N(θold)内,找到 L 的最大值对应的 θ 来更新参数。
应用在基于策略的强化学习中:
由于
J(θ)=ES[Vπ(S)]=ES[EA[π(A∣S;θold)π(A∣S;θ)⋅Qπ(S,A)]]
所以Approximation这一步可以这样做:
首先得到一个trajectory,蒙特卡洛近似:
L(θ∣θold)=n1i=1∑nπ(ai∣si;θold)π(ai∣si;θ)⋅Qπ(si,ai))
后面的Q可以用ui近似,这就完成了估计。
在Maximization这一步,可以选择邻域为∣∣θ−θold∣∣<Δ,也可以选择其他(如KL散度约束等)。
整个过程如下:
