论文阅读笔记:KCTS
| 题目 | Knowledge-Constrained Tree Search Decoding with Token-Level Hallucination Detection |
|---|---|
| 论文链接 | https://arxiv.org/abs/2310.09044 |
| 作者单位 | Department of Computer Science and Engineering, HKUST, Hong Kong SAR |
| 会议 | EMNLP2023 |
一篇幻觉检测并辅助解码的新文章。
介绍
以前的幻觉缓解工作许多都基于训练和微调。但是微调本来就比较麻烦,且可能造成灾难性遗忘等问题。即插即用的解码方法等工作又无法适应基于知识的场景,无法识别需要的知识。
提出了知识约束解码KCD,以及token级别的幻觉检测方法RIPA(Reward Inflection Point Approximation),用来预测幻觉的起始token。
问题陈述
y是生成的文本,x是输入,k是y必须被限制的知识,表示y对于k的真实性。
设表示生成的y对于k真实的分数,有(没看懂下面这个,估计是为了故事瞎弄的):
然后令牌级别的解码就变成:
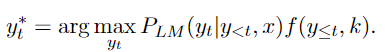
进一步定义:
其中y是基于的未来序列分布。
方法
蒙特卡洛树搜索解码
这个其实在前LLM时代已经被研究得比较多了。
选择
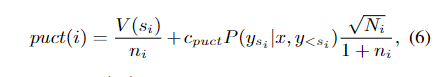
是节点的真实性。
扩展
选择前k个子节点扩展。
Rollout
如果模拟的话,就应该直接生成到EOS,然后,但是这里直接。
回传
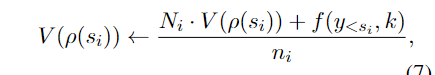
这里的ρ是父节点的意思。
重复这4个步骤,然后选择访问次数最高的根的子节点作为下一个token和树的下一个根(这里的根就是已生成文本)
token级别的幻觉检测
将f的求解视为 fact verification 的问题,以前的工作是随机截断或标token级别的幻觉数据。随机截断的问题是可能截断后不再是幻觉,但仍然是负样本;token标记则可能让模型把幻觉之前的好token也和幻觉联系起来(可以想象hades的训练)
RIPA
提出了 Reward Inflection-Point Approximation 来估计一个未完成序列的真实性。
幻觉有“Hallucination Snowballing”效应,即滚雪球,所以需要识别从哪里开始产生幻觉。
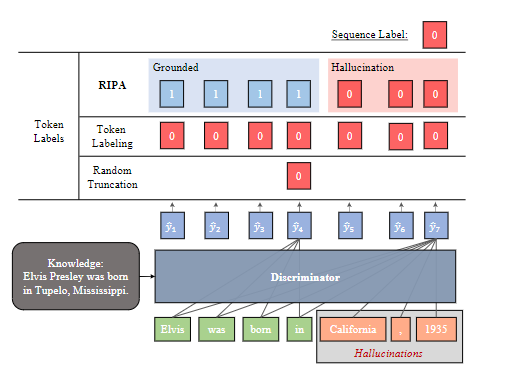
把幻觉出现前的token都标为0,可以避免检测器认为前面也是有幻觉的,其实也更有利于MCTS的搜索。
训练
数据是自动生成的:
- Knowledge Shuffle: 给一条数据(y, x, k),在数据集中随机替换知识源为 k’,作为 y + k’ 的负例。y的所有token都标为0。
- Partial Hallucination:和上面一样,交换后随机采样位置1<i<T,T是y的长度,然后截断。然后让模型依据生成,并且把温度调大于1,然后的部分标记为0.(这里我的理解应该是k是后面来的那个?所以新的y和原来的k是负例?)
然后训练数据是两者混合的,除了x和k无法区分的摘要生成,这个就只采取第二个。
Knowledge Weighted Decoding (KWD)
这是KCTS的姐妹方法。就是将RIPA替换为以前的解码方法的引导器。
以前的解码方法:FUDGE就是rerank top-k个token,但是分类器是用随机截断来训练的。
实验
基于知识的对话和摘要。
数据集
Knowledge Grounded Dialogue
使用the Wizard of Wikipedia WoW数据集的测试集。
Summarization
生成式摘要, CNN/DM数据集。
指标
token-based: BLEU-4, Rouge-L, ChrF, METEOR.
knowledge-based: Knowledge-F1(计算 y和k的unigram的F1)和K-Copy(LD是编辑距离的一种,度量y是不是只是机械地复制k)。
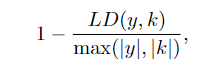
还使用了UniEval(使用布尔QA训练的基于model的评估器)。对于对话任务,将自然性、连贯性(与对话上下文)和事实性(已知事实)作为细粒度指标,对于摘要,将连贯性、一致性、流利性、相关性作为细粒度指标。
对于摘要,还使用MFMA,也是模型,和人类标签的相关性达到SOTA。
训练细节
用LoRA在FLAN-T5 XL上,只训练decoder层加一个线性层。(因为LoRA所以训练的参数比较少,这个使用这么大的模型做检测器有点bug哈哈,所以似乎还是有微调的,或者说只能使用于某个模型?)
结果
对话
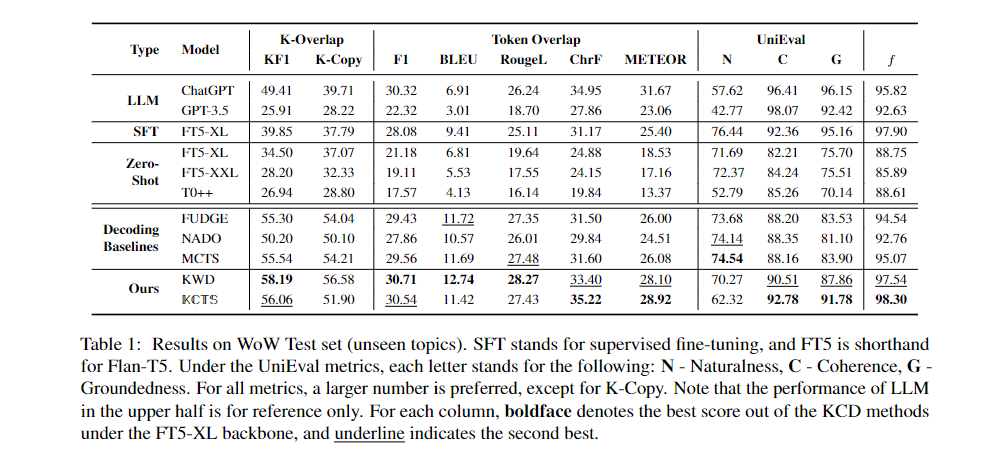
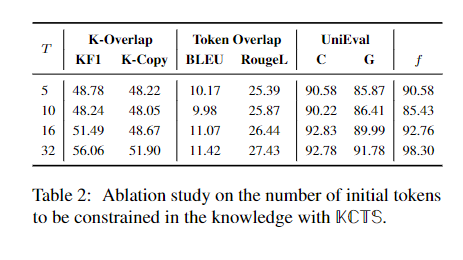
让KCTS先生成T个token,再让大模型核采样到结束,可以看到确实KCTS是能提高真实性的。
还有人类评估,就不说了。
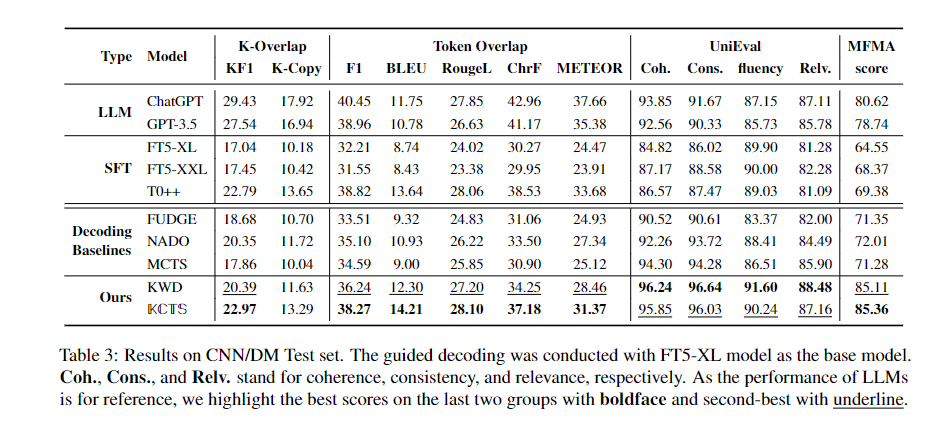
摘要
局限性
蒙特卡洛方法太慢,FUDGE的方法也得每个token要喂k个给检测器。
评价
这篇是多了knowledge的幻觉检测,看来还不是特别地任务通用,因为不是每个场景都会有knowledge的!
而且用FLAN-T5-XL做检测器,感觉很奇怪,太大了。